This is the multi-page printable view of this section. Click here to print.
Documentation
- 1: Kluctl
- 1.1: Get Started
- 1.2: Installation
- 1.3: Kluctl Projects
- 1.3.1: targets
- 1.4: Kluctl Library Projects
- 1.5: Deployments
- 1.5.1: Deployments
- 1.5.2: Kustomize Integration
- 1.5.3: Container Images
- 1.5.4: Helm Integration
- 1.5.5: OCI Support
- 1.5.6: SOPS Integration
- 1.5.7: Hooks
- 1.5.8: Readiness
- 1.5.9: Tags
- 1.5.10: Annotations
- 1.5.10.1: All resources
- 1.5.10.2: Hooks
- 1.5.10.3: Validation
- 1.5.10.4: Kustomize
- 1.6: Templating
- 1.6.1: Predefined Variables
- 1.6.2: Variable Sources
- 1.6.3: Filters
- 1.6.4: Functions
- 1.7: Commands
- 1.7.1: Common Arguments
- 1.7.2: Environment Variables
- 1.7.3: gitops deploy
- 1.7.4: gitops diff
- 1.7.5: controller install
- 1.7.6: list-targets
- 1.7.7: controller run
- 1.7.8: webui run
- 1.7.9: diff
- 1.7.10: deploy
- 1.7.11: prune
- 1.7.12: gitops logs
- 1.7.13: gitops prune
- 1.7.14: gitops reconcile
- 1.7.15: gitops resume
- 1.7.16: gitops suspend
- 1.7.17: gitops validate
- 1.7.18: oci push
- 1.7.19: delete
- 1.7.20: helm-pull
- 1.7.21: helm-update
- 1.7.22: list-images
- 1.7.23: poke-images
- 1.7.24: render
- 1.7.25: validate
- 1.7.26: webui build
- 2: Kluctl GitOps
- 2.1: Installation
- 2.2: Specs
- 2.2.1: v1beta1 specs
- 2.2.1.1: KluctlDeployment
- 2.3: Metrics
- 2.3.1: v1beta1 metrics
- 2.4: Kluctl Controller API reference
- 3: Kluctl Webui
- 3.1: Installation
- 3.2: Running locally
- 3.3: Azure AD Integration
- 4: Kluctl Recipes
- 5: Tutorials
- 5.1: Microservices Demo
- 5.1.1: 1. Basic Project Setup
- 5.1.2: 2. Helm Integration
- 5.1.3: 3. Templating and multi-env deployments
- 6: Examples
- 6.1: Simple
- 6.2: Simple Helm
- 6.3: Microservices demo
- 7: Template Controller
- 7.1: Installation
- 7.2: Specs
- 7.2.1: v1alpha1 specs
- 7.2.1.1: ObjectTemplate
- 7.2.1.2: GitProjector
- 7.2.1.3: GithubComment
- 7.2.1.4: GitlabComment
- 7.2.1.5: ListGithubPullRequests
- 7.2.1.6: TextTemplate
- 7.2.1.7: ListGitlabMergeRequests
- 7.3: Security
- 7.4: Templating
- 7.5: Use Case: Dynamic environments for Pull Requests
- 7.6: Use Case: Transformation of Secrets/Objects
- 7.7: Template Controller API reference
1 - Kluctl
What is Kluctl?
Kluctl is the missing glue that puts together your (and any third-party) deployments into one large declarative Kubernetes deployment, while making it fully manageable (deploy, diff, prune, delete, …) via one unified command line interface.
Core Concepts
These are some core concepts in Kluctl.
Kluctl project
The kluctl project defines targets. It is defined via the .kluctl.yaml configuration file.
Targets
A target defines a target cluster and a set of deployment arguments. Multiple targets can use the same cluster. Targets allow implementing multi-cluster, multi-environment, multi-customer, … deployments.
Deployments
A deployment defines which Kustomize deployments and which sub-deployments to deploy. It also controls the order of deployments.
Deployments may be configured through deployment arguments, which are typically provided via the targets but might also be provided through the CLI.
Variables
Variables are the main source of configuration. They are either loaded yaml files or directly defined inside deployments. Each variables file that is loaded has access to all the variables which were defined before, allowing complex composition of configuration.
After being loaded, variables are usable through the templating engine at all nearly all places.
Templating
All configuration files (including .kluctl.yaml and deployment.yaml) and all Kubernetes manifests involved are processed through a templating engine. The templating engine allows simple variable substitution and also complex control structures (if/else, for loops, …).
Unified CLI
The CLI of kluctl is designed to be unified/consistent as much as possible. Most commands are centered around targets
and thus require you to specify the target name (via -t <target>). If you remember how one command works, it’s easy
to figure out how the others work. Output from all targets based commands is also unified, allowing you to easily see
what will and what did happen.
History
Kluctl was created after multiple incarnations of complex multi-environment (e.g. dev, test, prod) deployments, including everything from monitoring, persistency and the actual custom services. The philosophy of these deployments was always “what belongs together, should be put together”, meaning that only as much Git repositories were involved as necessary.
The problems to solve turned out to be always the same:
- Dozens of Helm Charts, Kustomize deployments and standalone Kubernetes manifests needed to be orchestrated in a way that they work together (services need to connect to the correct databases, and so on)
- (Encrypted) Secrets needed to be managed and orchestrated for multiple environments and clusters
- Updates of components was always risky and required keeping track of what actually changed since the last deployment
- Available tools (Helm, Kustomize) were not suitable to solve this on its own in an easy/natural way
- A lot of Bash scripting was required to put things together
When this got more and more complex, and the bash scripts started to become a mess (as “simple” Bash scripts always tend to become), kluctl was started from scratch. It now tries to solve the mentioned problems and provide a useful set of features (commands) in a sane and unified way.
The first versions of kluctl were written in Python, hence the use of Jinja2 templating in kluctl. With version 2.0.0, kluctl was rewritten in Go.
1.1 - Get Started
This tutorial shows you how to start using kluctl.
Before you begin
A few things must be prepared before you actually begin.
Get a Kubernetes cluster
The first step is of course: You need a Kubernetes cluster. It doesn’t really matter where this cluster is hosted, if it’s a local (e.g. kind) cluster, managed cluster, or a self-hosted cluster, kops or kubespray based, AWS, GCE, Azure, … and so on. Kluctl is completely independent of how Kubernetes is deployed and where it is hosted.
There is however a minimum Kubernetes version that must be met: 1.20.0. This is due to the heavy use of server-side apply which was not stable enough in older versions of Kubernetes.
Prepare your kubeconfig
Your local kubeconfig should be configured to have access to the target Kubernetes cluster via a dedicated context. The context
name should match the name that you want to use for the cluster from now on. Let’s assume the name is test.example.com,
then you’d have to ensure that the kubeconfig context test.example.com is correctly pointing and authorized for this
cluster.
See Configure Access to Multiple Clusters for documentation on how to manage multiple clusters with a single kubeconfig. Depending on the Kubernetes provisioning/deployment tooling you used, you might also be able to directly export the context into your local kubeconfig. For example, kops is able to export and merge the kubeconfig for a given cluster.
Objectives
- Checkout one of the example Kluctl projects
- Deploy to your local cluster
- Change something and re-deploy
Install Kluctl
The kluctl command-line interface (CLI) is required to perform deployments. Read the installation instructions
to figure out how to install it.
Use Kluctl with a plain Kustomize deployment
The simplest way to test out Kluctl is to use an existing Kustomize deployment and just test out the CLI. For example, try it with the podtato-head project:
$ git clone https://github.com/podtato-head/podtato-head.git
$ cd podtato-head/delivery/kustomize/base
$ kluctl deploy
Then try to modify something inside the Kustomize deployment and retry the kluctl deploy call.
Try out the Kluctl examples
For more advanced examples, check out the Kluctl example projects. Clone the example project found at https://github.com/kluctl/kluctl-examples
$ git clone https://github.com/kluctl/kluctl-examples.git
Choose one of the examples
You can choose whatever example you like from the cloned repository. We will however continue this guide by referring
to the simple-helm example found in that repository.
Change directory:
$ cd kluctl-examples/simple-helm
Create your local cluster
Create a local cluster with kind:
$ kind create cluster
This will update your kubeconfig to contain a context with the name kind-kind. By default, all examples will use
the currently active context.
Deploy the example
Now run the following command to deploy the example:
$ kluctl deploy -t simple-helm
Kluctl will perform a diff first and then ask for your confirmation to deploy it. In this case, you should only see some objects being newly deployed.
$ kubectl -n simple-helm get pod
Change something and re-deploy
Now change something inside the deployment project. You could for example add replicaCount: 2 to deployment/nginx/helm-values.yml.
After you have saved your changes, run the deploy command again:
$ kluctl deploy -t simple-helm
This time it should show your modifications in the diff. Confirm that you want to perform the deployment and then verify it:
$ kubectl -n simple-helm get pod
You should need 2 instances of the nginx POD running now.
Where to continue?
Continue by reading through the recipes and tutorials. Also, consult the reference documentation for details about specifics.
1.2 - Installation
Kluctl is available as a CLI and as a GitOps controller.
Installing the CLI
Binaries
The kluctl CLI is available as a binary executable for all major platforms, the binaries can be downloaded form GitHub releases page.
Installation with Homebrew
With Homebrew for macOS and Linux:
$ brew install kluctl/tap/kluctl
Installation with Bash
With Bash for macOS and Linux:
$ curl -s https://kluctl.io/install.sh | bash
The install script does the following:
- attempts to detect your OS
- downloads and unpacks the release tar file in a temporary directory
- copies the kluctl binary to
/usr/local/bin - removes the temporary directory
Build from source
Clone the repository:
$ git clone https://github.com/kluctl/kluctl
$ cd kluctl
Build the kluctl binary (requires Go >= 1.19):
$ make build
Run the binary:
$ ./bin/kluctl -h
Container images
A container image with kluctl is available on GitHub:
ghcr.io/kluctl/kluctl:<version>
Installing the GitOps Controller
The controller can be installed via two available options.
Using the “install” sub-command
The kluctl controller install command can be used to install the
controller. It will use an embedded version of the Controller Kluctl deployment project
found here.
Using a Kluctl deployment
To manage and install the controller via Kluctl, you can use a Git include in your own deployment:
deployments:
- git:
url: https://github.com/kluctl/kluctl.git
subDir: install/controller
ref:
tag: v2.28.1
Installing the Kluctl Webui
See Installing the Kluctl Webui for details.
1.3 - Kluctl Projects
The .kluctl.yaml is the central configuration and entry point for your deployments. It defines which targets are
available to invoke commands on.
Example
An example .kluctl.yaml looks like this:
discriminator: "my-project-{{ target.name }}"
targets:
# test cluster, dev env
- name: dev
context: dev.example.com
args:
environment: dev
# test cluster, test env
- name: test
context: test.example.com
args:
environment: test
# prod cluster, prod env
- name: prod
context: prod.example.com
args:
environment: prod
args:
- name: environment
Allowed fields
discriminator
Specifies a default discriminator template to be used for targets that don’t have their own discriminator specified.
See target discriminator for details.
targets
Please check the targets sub-section for details.
args
A list of arguments that can or must be passed to most kluctl operations. Each of these arguments is then available
in templating via the global args object.
An example looks like this:
targets:
...
args:
- name: environment
- name: enable_debug
default: false
- name: complex_arg
default:
my:
nested1: arg1
nested2: arg2
These arguments can then be used in templating, e.g. by using {{ args.environment }}.
When calling kluctl, most of the commands will then require you to specify at least -a environment=xxx and optionally
-a enable_debug=true
The following sub chapters describe the fields for argument entries.
name
The name of the argument.
default
If specified, the argument becomes optional and will use the given value as default when not specified.
The default value can be an arbitrary yaml value, meaning that it can also be a nested dictionary. In that case, passing
args in nested form will only set the nested value. With the above example of complex_arg, running:
kluctl deploy -t my-target -a my.nested1=override`
will only modify the value below my.nested1 and keep the value of my.nested2.
aws
If specified, configures the default AWS configuration to use for awsSecretsManager vars sources and KMS based SOPS descryption.
Example:
aws:
profile: my-local-aws-profile
serviceAccount:
name: service-account-name
namespace: service-account-namespace
If any of the environment variables AWS_PROFILE, AWS_ACCESS_KEY_ID, AWS_ACCESS_KEY or AWS_WEB_IDENTITY_TOKEN_FILE
is set, Kluctl will ignore this AWS configuration and revert to using the environment variables based credentials.
profile
If specified, Kluctl will use this AWS config profile when found locally. If it is not found in your local AWS config, Kluctl will not try to use the specified profile.
serviceAccount
Optionally specifies the name and namespace of a service account to use for IRSA based authentication.
The specified service accounts needs to have the eks.amazonaws.com/role-arn annotation set to an existing IAM role
with a proper trust policy that allows this service account to assume that role. Please read the AWS documentation
for details.
The service account is only used when profile was not specified or when it is not present locally. If a service account is specified and accessible (you need proper RBAC access), Kluctl will not try to perform default AWS config loading.
Using Kluctl without .kluctl.yaml
It’s possible to use Kluctl without any .kluctl.yaml. In that case, all commands must be used without specifying the
target.
1.3.1 - targets
Specifies a list of targets for which commands can be invoked. A target puts together environment/target specific
configuration and the target cluster. Multiple targets can exist which target the same cluster but with differing
configuration (via args).
Each value found in the target definition is rendered with a simple Jinja2 context that only contains the target and args. The rendering process is retried 10 times until it finally succeeds, allowing you to reference the target itself in complex ways.
Target entries have the following form:
targets:
...
- name: <target_name>
context: <context_name>
args:
arg1: <value1>
arg2: <value2>
...
images:
- image: my-image
resultImage: my-image:1.2.3
aws:
profile: my-local-aws-profile
serviceAccount:
name: service-account-name
namespace: service-account-namespace
discriminator: "my-project-{{ target.name }}"
...
The following fields are allowed per target:
name
This field specifies the name of the target. The name must be unique. It is referred in all commands via the -t option.
context
This field specifies the kubectl context of the target cluster. The context must exist in the currently active kubeconfig. If this field is omitted, Kluctl will always use the currently active context.
args
This fields specifies a map of arguments to be passed to the deployment project when it is rendered. Allowed argument names are configured via deployment args.
images
This field specifies a list of fixed images to be used by images.get_image(...).
The format is identical to the fixed images file.
aws
This field specifies target specific AWS configuration, which overrides what was optionally specified via the global AWS configuration.
discriminator
Specifies a discriminator which is used to uniquely identify all deployed objects on the cluster. It is added to all
objects as the value of the kluctl.io/discriminator label. This label is then later used to identify all objects
belonging to the deployment project and target, so that Kluctl can determine which objects got orphaned and need to
be pruned. The discriminator is also used to identify all objects that need to be deleted when
kluctl delete is called.
If no discriminator is set for a target, kluctl prune and kluctl delete are not supported.
The discriminator can be a template which is rendered at project loading time. While
rendering, only the target and args are available as global variables in the templating context.
The rendered discriminator should be unique on the target cluster to avoid mis-identification of objects from other
deployments or targets. It’s good practice to prefix the discriminator with a project name and at least use the target
name to make it unique. Example discriminator to achieve this: my-project-name-{{ target.name }}.
If a target is meant to be deployed multiple times, e.g. by using external arguments, the external
arguments should be taken into account as well. Example: my-project-name-{{ target.name }}-{{ args.environment_name }}.
A default discriminator can also be specified which is used whenever a target has no discriminator configured.
1.4 - Kluctl Library Projects
A library project is a Kluctl deployment that is meant to be included by other projects. It can be provided with configuration either via args or via vars in the include.
Kluctl deployment projects can include these library projects via local include, Git include or Oci includes. artifacts.
The .kluctl-library.yaml marks a deployment project as a library project and provides some configuration.
Example
Consider the following root deployment.yaml inside your root project:
deployments:
- git:
url: git@github.com:example/example-library.git
args:
arg1: value1
And the following .kluctl-library.yaml inside the included example-library git project:
args:
- name: arg1
- name: arg2
default: value2
This will include the given git repository and make args.arg1 and args.arg2 available via templating.
Allowed fields
args
A list of arguments that can or must be passed when including the library project. Each of these arguments is then available
in templating via the global args object.
An example looks like this:
args:
- name: environment
- name: enable_debug
default: false
- name: complex_arg
default:
my:
nested1: arg1
nested2: arg2
The meaning and function of these arguements is identical to the args in .kluctl.yaml.
Using Kluctl Libraries without .kluctl-library.yaml
Includes can also be done on projects that do not have a .kluctl-library.yaml configuration. In that case, all
currently available variables are passed into the include project, including the args from the root deployment project.
1.5 - Deployments
A deployment project is a collection of deployment items and sub-deployments. Deployment items are usually Kustomize deployments, but can also integrate Helm Charts.
Basic structure
The following visualization shows the basic structure of a deployment project. The entry point of every deployment
project is the deployment.yaml file, which then includes further sub-deployments and kustomize deployments. It also
provides some additional configuration required for multiple kluctl features to work as expected.
As can be seen, sub-deployments can include other sub-deployments, allowing you to structure the deployment project as you need.
Each level in this structure recursively adds tags to each deployed resources, allowing you to control precisely what is deployed in the future.
-- project-dir/
|-- deployment.yaml
|-- .gitignore
|-- kustomize-deployment1/
| |-- kustomization.yaml
| `-- resource.yaml
|-- sub-deployment/
| |-- deployment.yaml
| |-- kustomize-deployment2/
| | |-- resource1.yaml
| | `-- ...
| |-- kustomize-deployment3/
| | |-- kustomization.yaml
| | |-- resource1.yaml
| | |-- resource2.yaml
| | |-- patch1.yaml
| | `-- ...
| |-- kustomize-with-helm-deployment
| | |-- charts/
| | | `-- ...
| | |-- kustomization.yaml
| | |-- helm-chart.yaml
| | `-- helm-values.yaml
| `-- subsub-deployment/
| |-- deployment.yaml
| |-- ... kustomize deployments
| `-- ... subsubsub deployments
`-- sub-deployment/
`-- ...
Order of deployments
Deployments are done in parallel, meaning that there are usually no order guarantees. The only way to somehow control order, is by placing barriers between kustomize deployments. You should however not overuse barriers, as they negatively impact the speed of kluctl.
Plain Kustomize
It’s also possible to use Kluctl on plain Kustomize deployments. Simply run kluctl deploy from inside the
folder of your kustomization.yaml. If you also don’t have a .kluctl.yaml, you can also work without targets.
Please note that pruning and deletion is not supported in this mode.
1.5.1 - Deployments
The deployment.yaml file is the entrypoint for the deployment project. Included sub-deployments also provide a
deployment.yaml file with the same structure as the initial one.
An example deployment.yaml looks like this:
deployments:
- path: nginx
- path: my-app
- include: monitoring
- git:
url: git@github.com:example/example.git
- oci:
url: oci://ghcr.io/kluctl/kluctl-examples/simple
commonLabels:
my.prefix/target: "{{ target.name }}"
my.prefix/deployment-project: my-deployment-project
The following sub-chapters describe the available fields in the deployment.yaml
deployments
deployments is a list of deployment items. Multiple deployment types are supported, which is documented further down.
Individual deployments are performed in parallel, unless a barrier is encountered which causes kluctl to
wait for all previous deployments to finish.
Deployments can also be conditional by using the when field.
Simple deployments
Simple deployments are specified via path and are expected to be directories with Kubernetes manifests inside.
Kluctl will internally generate a kustomization.yaml from these manifests and treat the deployment item the same way
as it would treat a Kustomize deployment.
Example:
deployments:
- path: path/to/manifests
If the manifests are stored in a nested directory structure (for example, when using the Rendered Manifests Pattern), you can configure Kluctl to recursively walk and discover manifests by setting recursive: true.
Note that recursive: true is mutually exclusive with having a kustomization.yaml or kustomization.yml in the root directory of the deployment item. If a root kustomization file is present, setting recursive: true will result in a validation error.
Example:
deployments:
- path: path/to/manifests
recursive: true
Kustomize deployments
When the deployment item directory specified via path contains a kustomization.yaml, Kluctl will use this file
instead of generating one.
Please see Kustomize integration for more details.
Example:
deployments:
- path: path/to/deployment1
- path: path/to/deployment2
The path must point to a directory relative to the directory containing the deployment.yaml. Only directories
that are part of the kluctl project are allowed. The directory must contain a valid kustomization.yaml.
Includes
Specifies a sub-deployment project to be included. The included sub-deployment project will inherit many properties of the parent project, e.g. tags, commonLabels and so on.
Example:
deployments:
- include: path/to/sub-deployment
The path must point to a directory relative to the directory containing the deployment.yaml. Only directories
that are part of the kluctl project are allowed. The directory must contain a valid deployment.yaml.
Git includes
Specifies an external git project to be included. The project is included the same way with regular includes, except that the included project can not use/load templates from the parent project. An included project might also include further git projects.
If the included project is a Kluctl Library Project, current variables are NOT passed automatically into the included project. Only when passVars is set to true, all current variables are passed. For library projects, args is the preferred way to pass configuration.
Simple example:
deployments:
- git: git@github.com:example/example.git
This will clone the git repository at git@github.com:example/example.git, checkout the default branch and include it
into the current project.
Advanced Example:
deployments:
- git:
url: git@github.com:example/example.git
ref:
branch: my-branch
subDir: some/sub/dir
The url specifies the Git url to be cloned and checked out.
ref is optional and specifies the branch or tag to be used. To specify a branch, set the sub-field branch as seen
in the above example. To pass a tag, set the tag field instead. To pass a commit, set the commit field instead.
If ref is omitted, the default branch will be checked out.
subDir is optional and specifies the sub directory inside the git repository to include.
OCI includes
Specifies an OCI based artifact to include. The artifact must be pushed to your OCI repository via the
kluctl oci push command. The artifact is extracted and then included the same way a
git include is included.
If the included project is a Kluctl Library Project, current variables are NOT passed automatically into the included project. Only when passVars is set to true, all current variables are passed. For library projects, args is the preferred way to pass configuration.
Simple example:
deployments:
- oci:
url: oci://ghcr.io/kluctl/kluctl-examples/simple
The url specifies the OCI repository url. It must use the oci:// scheme. It is not allowed to add tags or digests to
the url. Instead, use the dedicated ref field:
deployments:
- oci:
url: oci://ghcr.io/kluctl/kluctl-examples/simple
ref:
tag: latest
For digests, use:
deployments:
- oci:
url: oci://ghcr.io/kluctl/kluctl-examples/simple
ref:
digest: sha256:9ac3ba762c373ebccecb9dd3ac1d8ca091e4bd4a101701ce99e6058c0c74eedc
Subdirectories of the pushed artifact can be specified via subDir:
deployments:
- oci:
url: oci://ghcr.io/kluctl/kluctl-examples/simple
subDir: my-subdir
See OCI support for more details, especially in regard to authentication for private registries.
Barriers
Causes kluctl to wait until all previous kustomize deployments have been applied. This is useful when upcoming deployments need the current or previous deployments to be finished beforehand. Previous deployments also include all sub-deployments from included deployments.
Please note that barriers do not wait for readiness of individual resources. This means that it will not wait for
readiness of services, deployments, daemon sets, and so on. To actually wait for readiness, use waitReadiness: true or
waitReadinessObjects.
Example:
deployments:
- path: kustomizeDeployment1
- path: kustomizeDeployment2
- include: subDeployment1
- barrier: true
# At this point, it's ensured that kustomizeDeployment1, kustomizeDeployment2 and all sub-deployments from
# subDeployment1 are fully deployed.
- path: kustomizeDeployment3
To create a barrier with a custom message, include the message parameter when creating the barrier. The message parameter accepts a string value that represents the custom message.
Example:
deployments:
- path: kustomizeDeployment1
- path: kustomizeDeployment2
- include: subDeployment1
- barrier: true
message: "Waiting for subDeployment1 to be finished"
# At this point, it's ensured that kustomizeDeployment1, kustomizeDeployment2 and all sub-deployments from
# subDeployment1 are fully applied.
- path: kustomizeDeployment3
If no custom message is provided, the barrier will be created without a specific message, and the default behavior will be applied.
When viewing the kluctl deploy status, the custom message, if provided, will be displayed along with default barrier information.
waitReadiness
waitReadiness can be set on all deployment items. If set to true, Kluctl will wait for readiness of each individual object
of the current deployment item. Readiness is defined in readiness.
Please note that Kluctl will not wait for readiness of previous deployment items.
This can also be combined with barriers, which will instruct Kluctl to stop processing the next deployment items until everything before the barrier is applied and the current deployment item’s objects are all ready.
Examples:
deployments:
- path: kustomizeDeployment1
waitReadiness: true
- path: kustomizeDeployment2
# this will wait for kustomizeDeployment1 to be applied+ready and kustomizeDeployment2 to be applied
# kustomizeDeployment2 is not guaranteed to be ready at this point, but might be due to the parallel nature of Kluctl
- barrier: true
- path: kustomizeDeployment3
waitReadinessObjects
This is comparable to waitReadiness, but instead of waiting for all objects of the current deployment item, it allows
to explicitly specify objects which are not necessarily part of the current (or any) deployment item.
This is for example useful if you used an external Helm Chart and want to wait for readiness of some individual objects, e.g. CRDs that are being deployment by some in-cluster operator instead of the Helm chart itself.
Examples:
deployments:
# The cilium Helm chart does not deploy CRDs anymore. Instead, the cilium-operator does this on startup. This means,
# we can't apply CiliumNetworkPolicies before the CRDs get applied by the operator.
- path: cilium
- barrier: true
waitReadinessObjects:
- kind: Deployment
name: cilium-operator
namespace: kube-system
- kind: CustomResourceDefinition
name: ciliumnetworkpolicies.cilium.io
# This deployment can now safely use the CRDs applied by the operator
- path: kustomizeDeployment1
deleteObjects
Causes kluctl to delete matching objects, specified by a list of group/kind/name/namespace dictionaries. The order/parallelization of deletion is identical to the order and parallelization of normal deployment items, meaning that it happens in parallel by default until a barrier is encountered.
Example:
deployments:
- deleteObjects:
- group: apps
kind: DaemonSet
namespace: kube-system
name: kube-proxy
- barrier: true
- path: my-cni
The above example shows how to delete the kube-proxy DaemonSet before installing a CNI (e.g. Cilium in proxy-replacement mode).
deployments common properties
All entries in deployments can have the following common properties:
vars (deployment item)
A list of variable sets to be loaded into the templating context, which is then available in all deployment items and sub-deployments.
See templating for more details.
Example:
deployments:
- path: kustomizeDeployment1
vars:
- file: vars1.yaml
- values:
var1: value1
- path: kustomizeDeployment2
# all sub-deployments of this include will have the given variables available in their Jinj2 context.
- include: subDeployment1
vars:
- file: vars2.yaml
passVars
Can only be used on include, git include and oci include. If set to true,
all variables will be passed down to the included project even if the project is an explicitly marked
Kluctl Library Project.
If the included project is not a library project, variables are always fully passed into the included deployment.
args
Can only be used on include, git include and oci include. Passes the given arguments into Kluctl Library Projects.
when
Each deployment item can be conditional with the help of the when field. It must be set to a
Jinja2 based expression
that evaluates to a boolean.
Example:
deployments:
- path: item1
- path: item2
when: my.var == "my-value"
tags (deployment item)
A list of tags the deployment should have. See tags for more details. For includes, this means that all sub-deployments will get these tags applied to. If not specified, the default tags logic as described in tags is applied.
Example:
deployments:
- path: kustomizeDeployment1
tags:
- tag1
- tag2
- path: kustomizeDeployment2
tags:
- tag3
# all sub-deployments of this include will get tag4 applied
- include: subDeployment1
tags:
- tag4
alwaysDeploy
Forces a deployment to be included everytime, ignoring inclusion/exclusion sets from the command line. See Deploying with tag inclusion/exclusion for details.
deployments:
- path: kustomizeDeployment1
alwaysDeploy: true
- path: kustomizeDeployment2
Please note that alwaysDeploy will also cause kluctl render to always render the resources.
skipDeleteIfTags
Forces exclusion of a deployment whenever inclusion/exclusion tags are specified via command line. See Deleting with tag inclusion/exclusion for details.
deployments:
- path: kustomizeDeployment1
skipDeleteIfTags: true
- path: kustomizeDeployment2
onlyRender
Causes a path to be rendered only but not treated as a deployment item. This can be useful if you for example want to use Kustomize components which you’d refer from other deployment items.
deployments:
- path: component
onlyRender: true
- path: kustomizeDeployment2
vars (deployment project)
A list of variable sets to be loaded into the templating context, which is then available in all deployment items and sub-deployments.
See templating for more details.
commonLabels
A dictionary of labels and values to be added to all resources deployed by any of the deployment items in this deployment project.
Consider the following example deployment.yaml:
deployments:
- path: nginx
- include: sub-deployment1
commonLabels:
my.prefix/target: {{ target.name }}
my.prefix/deployment-name: my-deployment-project-name
my.prefix/label-1: value-1
my.prefix/label-2: value-2
Every resource deployed by the kustomize deployment nginx will now get the four provided labels attached. All included
sub-deployment projects (e.g. sub-deployment1) will also recursively inherit these labels and pass them further
down.
In case an included sub-deployment project also contains commonLabels, both dictionaries of commonLabels are merged
inside the included sub-deployment project. In case of conflicts, the included common labels override the inherited.
Please note that these commonLabels are not related to commonLabels supported in kustomization.yaml files. It was
decided to not rely on this feature but instead attach labels manually to resources right before sending them to
kubernetes. This is due to an implementation detail in
kustomize which causes commonLabels to also be applied to label selectors, which makes otherwise editable resources
read-only when it comes to commonLabels.
commonAnnotations
A dictionary of annotations and values to be added to all resources deployed by any of the deployment items in this deployment project.
commonAnnotations are handled the same as commonLabels in regard to inheriting, merging and overriding.
overrideNamespace
A string that is used as the default namespace for all kustomize deployments which don’t have a namespace set in their
kustomization.yaml.
tags (deployment project)
A list of common tags which are applied to all kustomize deployments and sub-deployment includes.
See tags for more details.
ignoreForDiff
A list of rules used to determine which differences should be ignored in diff outputs.
As an alternative, annotations can be used to control diff behavior of individual resources.
Consider the following example:
deployments:
- ...
ignoreForDiff:
- kind: Deployment
name: my-deployment
fieldPath: spec.replicas
This will ignore differences for the spec.replicas field in the Deployment with the name my-deployment.
Using regex expressions instead of JSON Pathes is also supported:
deployments:
- ...
ignoreForDiff:
- kind: Deployment
name: my-deployment
fieldPathRegex: metadata.labels.my-label-.*
The following properties are supported in ignoreForDiff items.
fieldPath
If specified, must be a valid JSON Path. Kluctl will ignore differences for all matching fields of all matching objects (see the other properties).
Either fieldPath or fieldPathRegex must be provided.
fieldPathRegex
If specified, must be a valid regex. Kluctl will ignore differences for all matching fields of all matching objects (see the other properties).
Either fieldPath or fieldPathRegex must be provided.
group
This property is optional. If specified, only objects with a matching api group will be considered. Please note that this field should NOT include the version of the api group.
kind
This property is optional. If specified, only objects with a matching kind will be considered.
namespace
This property is optional. If specified, only objects with a matching namespace will be considered.
name
This property is optional. If specified, only objects with a matching name will be considered.
conflictResolution
A list of rules used to determine how to handle conflict resolution.
As an alternative, annotations can be used to control conflict resolution of individual resources.
Consider the following example:
deployments:
- ...
conflictResolution:
- kind: ValidatingWebhookConfiguration
fieldPath: webhooks.*.*
action: ignore
This will cause Kluctl to ignore conflicts on all matching fields of all ValidatingWebhookConfiguration objects.
Using regex expressions instead of JSON Pathes is also supported:
deployments:
- ...
conflictResolution:
- kind: ValidatingWebhookConfiguration
fieldPathRegex: webhooks\..
action: ignore
In some cases, it’s easier to match fields by manager name:
deployments:
- ...
conflictResolution:
- manager: clusterrole-aggregation-controller
action: ignore
- manager: cert-manager-cainjector
action: ignore
The following properties are supported in conflictResolution items.
fieldPath
If specified, must be a valid JSON Path. Kluctl will ignore conflicts for all matching fields of all matching objects (see the other properties).
Either fieldPath, fieldPathRegex or manager must be provided.
fieldPathRegex
If specified, must be a valid regex. Kluctl will ignore conflicts for all matching fields of all matching objects (see the other properties).
Either fieldPath, fieldPathRegex or manager must be provided.
manager
If specified, must be a valid regex. Kluctl will ignore conflicts for all fields that currently have a matching field manager assigned. This is useful if a mutating webhook or controller is known to modify fields after they have been applied.
Either fieldPath, fieldPathRegex or manager must be provided.
action
This field is required and must be either ignore or force-apply.
group
This property is optional. If specified, only objects with a matching api group will be considered. Please note that this field should NOT include the version of the api group.
kind
This property is optional. If specified, only objects with a matching kind will be considered.
namespace
This property is optional. If specified, only objects with a matching namespace will be considered.
name
This property is optional. If specified, only objects with a matching name will be considered.
1.5.2 - Kustomize Integration
kluctl uses kustomize to render final resources. This means, that the finest/lowest level in kluctl is represented with kustomize deployments. These kustomize deployments can then perform further customization, e.g. patching and more. You can also use kustomize to easily generate ConfigMaps or secrets from files.
Generally, everything is possible via kustomization.yaml, is thus possible in kluctl.
We advise to read the kustomize reference. You can also look into the official kustomize example.
Using the Kustomize Integration
Please refer to the Kustomize Deployment Item documentation for details.
1.5.3 - Container Images
There are usually 2 different scenarios where Container Images need to be specified:
- When deploying third party applications like nginx, redis, … (e.g. via the Helm integration).
- In this case, image versions/tags rarely change, and if they do, this is an explicit change to the deployment. This means it’s fine to have the image versions/tags directly in the deployment manifests.
- When deploying your own applications.
- In this case, image versions/tags might change very rapidly, sometimes multiple times per hour. Having these versions/tags directly in the deployment manifests can easily lead to commit spam and hard to manage multi-environment deployments.
kluctl offers a better solution for the second case.
images.get_image()
This is solved via a templating function that is available in all templates/resources. The function is part of the global
images object and expects the following arguments:
images.get_image(image)
- image
- The image name/repository. It is looked up the list of fixed images.
The function will lookup the given image in the list of fixed images and return the last match.
Example deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
template:
spec:
containers:
- name: c1
image: "{{ images.get_image('registry.gitlab.com/my-group/my-project') }}"
Fixed images
Fixed images can be configured multiple methods:
- Command line argument
--fixed-image - Command line argument
--fixed-images-file - Target definition
- Global ‘images’ variable
Command line argument --fixed-image
You can pass fixed images configuration via the --fixed-image argument.
Due to environment variables support in the CLI, you can also use the
environment variable KLUCTL_FIXED_IMAGE_XXX to configure fixed images.
The format of the --fixed-image argument is --fixed-image image<:namespace:deployment:container>=result. The simplest
example is --fixed-image registry.gitlab.com/my-group/my-project=registry.gitlab.com/my-group/my-project:1.1.2.
Command line argument --fixed-images-file
You can also configure fixed images via a yaml file by using --fixed-images-file /path/to/fixed-images.yaml.
file:
images:
- image: registry.gitlab.com/my-group/my-project
resultImage: registry.gitlab.com/my-group/my-project:1.1.2
The file must contain a single root list named images with each entry having the following form:
images:
- image: <image_name>
resultImage: <result_image>
# optional fields
namespace: <namespace>
deployment: <kind>/<name>
container: <name>
image (or imageRegex) and resultImage are required. All the other fields are optional and allow to specify in detail for which
object the fixed is specified.
You can also specify a regex for the image name:
images:
- imageRegex: registry\.gitlab\.com/my-group/.*
resultImage: <result_image>
# optional fields
namespace: <namespace>
deployment: <kind>/<name>
container: <name>
Target definition
The target definition can optionally specify an images field that can
contain the same fixed images configuration as found in the --fixed-images-file file.
Global ‘images’ variable
You can also define a global variable named images via one of the variable sources.
This variable must be a list of the same format as the images list in the --fixed-images-file file.
This option allows to externalize fixed images configuration, meaning that you can maintain image versions outside the deployment project, e.g. in another Git repository.
1.5.4 - Helm Integration
kluctl offers a simple-to-use Helm integration, which allows you to reuse many common third-party Helm Charts.
The integration is split into 2 parts/steps/layers. The first is the management and pulling of the Helm Charts, while the second part handles configuration/customization and deployment of the chart.
It is recommended to pre-pull Helm Charts with kluctl helm-pull, which will store the
pulled charts inside .helm-charts of the project directory. It is however also possible (but not
recommended) to skip the pre-pulling phase and let kluctl pull Charts on-demand.
When pre-pulling Helm Charts, you can also add the resulting Chart contents into version control. This is actually recommended as it ensures that the deployment will always behave the same. It also allows pull-request based reviews on third-party Helm Charts.
How it works
Helm charts are not directly installed via Helm. Instead, kluctl renders the Helm Chart into a single file and then
hands over the rendered yaml to kustomize. Rendering is done in combination with a provided
helm-values.yaml, which contains the necessary values to configure the Helm Chart.
The resulting rendered yaml is then referred by your kustomization.yaml, from which point on the
kustomize integration
takes over. This means, that you can perform all desired customization (patches, namespace override, …) as if you
provided your own resources via yaml files.
Helm hooks
Helm Hooks are implemented by mapping them to kluctl hooks, based on the following mapping table:
| Helm hook | kluctl hook |
|---|---|
| pre-install | pre-deploy-initial |
| post-install | post-deploy-initial |
| pre-delete | Not supported |
| post-delete | Not supported |
| pre-upgrade | pre-deploy-upgrade |
| post-upgrade | post-deploy-upgrade |
| pre-rollback | Not supported |
| post-rollback | Not supported |
| test | Not supported |
Please note that this is a best effort approach and not 100% compatible to how Helm would run hooks.
helm-chart.yaml
The helm-chart.yaml defines where to get the chart from, which version should be pulled, the rendered output file name,
and a few more Helm options. After this file is added to your project, you need to invoke the helm-pull command
to pull the Helm Chart into your local project. It is advised to put the pulled Helm Chart into version control, so
that deployments will always be based on the exact same Chart (Helm does not guarantee this when pulling).
Example helm-chart.yaml:
helmChart:
repo: https://charts.bitnami.com/bitnami
chartName: redis
chartVersion: 12.1.1
updateConstraints: ~12.1.0
skipUpdate: false
skipPrePull: false
releaseName: redis-cache
namespace: "{{ my.jinja2.var }}"
output: helm-rendered.yaml # this is optional
The same filename that was specified in output must then be referred in a kustomization.yaml as a normal local
resource. If output is omitted, the default value helm-rendered.yaml is used and must also be referenced in
kustomization.yaml.
helmChart inside helm-chart.yaml supports the following fields:
repo
The url to the Helm repository where the Helm Chart is located. You can use hub.helm.sh to search for repositories and charts and then use the repos found there.
OCI based repositories are also supported, for example:
helmChart:
repo: oci://r.myreg.io/mycharts/pepper
chartVersion: 1.2.3
releaseName: pepper
namespace: pepper
path
As alternative to repo, you can also specify path. The path must point to a local Helm Chart that is relative to the
helm-chart.yaml. The local Chart must reside in your Kluctl project.
When path is specified, repo, chartName, chartVersion and updateContrainsts are not allowed.
chartName
The name of the chart that can be found in the repository.
chartVersion
The version of the chart. Must be a valid semantic version.
git
Instead of using repo for OCI/Helm registries or path for local charts, you can also pull Charts from Git repositories.
This is helpful in cases where you don’t want to publish a chart to a registry or as page, e.g. because of the overhead or other internal restrictions.
You have to set the url as well as the branch, tag or commit. If the chart itself is in a sub directory, you can also specify a subDir:
helmChart:
git:
url: https://github.com/mycharts/salt
ref:
branch: main
#tag: v1.0.0 -- branch, tag and commit are mutually exclusive
#commit: 015244630b53eb69d77858e5587641b741e91706 -- branch, tag and commit are mutually exclusive
subDir: charts/path/to/chart
releaseName: salt
namespace: salt
In order to be able to use the helm-update command, the branch or tag has to be semantic. If this is not the case, the update is skipped.
updateConstraints
Specifies version constraints to be used when running helm-update. See Checking Version Constraints for details on the supported syntax.
If omitted, Kluctl will filter out pre-releases by default. Use a updateConstraints like ~1.2.3-0 to enable
pre-releases.
skipUpdate
If set to true, skip this Helm Chart when the helm-update command is called.
If omitted, defaults to false.
skipPrePull
If set to true, skip pre-pulling of this Helm Chart when running helm-pull. This will
also enable pulling on-demand when the deployment project is rendered/deployed.
releaseName
The name of the Helm Release.
namespace
The namespace that this Helm Chart is going to be deployed to. Please note that this should match the namespace
that you’re actually deploying the kustomize deployment to. This means, that either namespace in kustomization.yaml
or overrideNamespace in deployment.yaml should match the namespace given here. The namespace should also be existing
already at the point in time when the kustomize deployment is deployed.
output
This is the file name into which the Helm Chart is rendered into. Your kustomization.yaml should include this same
file. The file should not be existing in your project, as it is created on-the-fly while deploying.
skipCRDs
If set to true, kluctl will pass --skip-crds to Helm when rendering the deployment. If set to false (which is
the default), kluctl will pass --include-crds to Helm.
helm-values.yaml
This file should be present when you need to pass custom Helm Value to Helm while rendering the deployment. Please read the documentation of the used Helm Charts for details on what is supported.
Updates to helm-charts
In case a Helm Chart needs to be updated, you can either do this manually by replacing the chartVersion
value in helm-chart.yaml and the calling the helm-pull command or by simply invoking
helm-update with --upgrade and/or --commit being set.
Private Repositories
It is also possible to use private chart repositories and private OCI registries. There are multiple options to provide credentials to Kluctl.
Use helm repo add --username xxx --password xxx before
Kluctl will try to find known repositories that are managed by the Helm CLI and then try to reuse the credentials of
these. The repositories are identified by the URL of the repository, so it doesn’t matter what name you used when you
added the repository to Helm. The same method can be used for client certificate based authentication (--key-file
in helm repo add).
Use helm registry login --username xxx --password xxx for OCI registries
The same as for helm repo add applies here, except that authentication entries are matched by hostname.
Use docker login for OCI registries
Kluctl tries to use credentials stored in $HOME/.docker/config.json as well, so
docker login will also allow Kluctl to authenticate
against OCI registries.
Use the –helm-xxx and –registry-xxx arguments of Kluctl sub-commands
All commands that interact with Helm Chart repositories and OCI registries support the helm arguments and registry arguments to specify authentication per repository and/or OCI registry.
Use environment variables to specify authentication
You can also use environment variables to specify Helm Chart repository authentication. For OCI based registries, see OCI authentication for details.
The following environment variables are supported:
KLUCTL_HELM_HOST: Specifies the host name of the repository to match before the specified credentials are considered.KLUCTL_HELM_PATH: Specifies the path to match before the specified credentials are considered. If omitted, credentials are applied to all matching hosts. Can contain wildcards.KLUCTL_HELM_USERNAME: Specifies the username.KLUCTL_HELM_PASSWORD: Specifies the password.KLUCTL_HELM_INSECURE_SKIP_TLS_VERIFY: If set totrue, Kluctl will skip TLS verification for matching repositories.KLUCTL_HELM_PASS_CREDENTIALS_ALL: If set totrue, Kluctl will instruct Helm to pass credentials to all domains. See https://helm.sh/docs/helm/helm_repo_add/ for details.KLUCTL_HELM_CERT_FILE: Specifies the client certificate to use while connecting to the matching repository.KLUCTL_HELM_KEY_FILE: Specifies the client key to use while connecting to the matching repository.KLUCTL_HELM_CA_FILE: Specifies CA bundle to use for TLS/https verification.
Multiple credential sets can be specified by including an index in the environment variable names, e.g.
KLUCTL_HELM_1_HOST=host.org, KLUCTL_HELM_1_USERNAME=my-user and KLUCTL_HELM_1_PASSWORD=my-password will apply
the given credential to all repositories with the host host.org, while KLUCTL_HELM_2_HOST=other.org,
KLUCTL_HELM_2_USERNAME=my-other-user and KLUCTL_HELM_2_PASSWORD=my-other-password will apply the other credentials
to the other.org repository.
Credentials when using the kluctl-controller
In case you want to use the same Kluctl deployment via the kluctl-controller, you have to
configure Helm and OCI credentials via spec.credentials.
Templating
Both helm-chart.yaml and helm-values.yaml are rendered by the templating engine before they
are actually used. This means, that you can use all available Jinja2 variables at that point, which can for example be
seen in the above helm-chart.yaml example for the namespace.
There is however one exception that leads to a small limitation. When helm-pull reads the helm-chart.yaml, it does
NOT render the file via the templating engine. This is because it can not know how to properly render the template as it
does have no information about targets (there are no -t arguments set) at that point.
This exception leads to the limitation that the helm-chart.yaml MUST be valid yaml even in case it is not rendered
via the templating engine. This makes using control statements (if/for/…) impossible in this file. It also makes it
a requirement to use quotes around values that contain templates (e.g. the namespace in the above example).
helm-values.yaml is not subject to these limitations as it is only interpreted while deploying.
1.5.5 - OCI Support
Kluctl provides OCI support in multiple places. See the following sections for details.
Helm OCI based registries
Kluctl fully supports OCI based Helm registries in the Helm integration.
OCI includes
Kluctl can include sub-deployments from OCI artifacts via OCI includes.
These artifacts can be pushed via the kluctl oci push sub-command.
Authentication
Private registries are supported as well. To authenticate to these, use one of the following methods.
Authenticate via --registry-xxx arguments
All commands that interact with OCI registries support the registry arguments to specify authentication per OCI registry.
Authenticate via docker login
Kluctl tries to use credentials stored in $HOME/.docker/config.json as well, so
docker login will also allow Kluctl to authenticate
against OCI registries.
Use environment variables to specify authentication
You can also use environment variables to specify OCI authentication.
The following environment variables are supported:
KLUCTL_REGISTRY_HOST: Specifies the registry host name to match before the specified credentials are considered.KLUCTL_REGISTRY_REPOSITORY: Specifies the repository name to match before the specified credentials are considered. The repository name can contain the organization name, which default tolibraryis omitted. Can contain wildcards.KLUCTL_REGISTRY_USERNAME: Specifies the username.KLUCTL_REGISTRY_PASSWORD: Specifies the password.KLUCTL_REGISTRY_IDENTITY_TOKEN: Specifies the identity token used for authentication.KLUCTL_REGISTRY_TOKEN: Specifies the bearer token used for authentication.KLUCTL_REGISTRY_INSECURE_SKIP_TLS_VERIFY: If set totrue, Kluctl will skip TLS verification for matching registries.KLUCTL_REGISTRY_PLAIN_HTTP: If set totrue, forces the use of http (no TLS).KLUCTL_REGISTRY_CERT_FILE: Specifies the client certificate to use while connecting to the matching repository.KLUCTL_REGISTRY_KEY_FILE: Specifies the client key to use while connecting to the matching repository.KLUCTL_REGISTRY_CA_FILE: Specifies CA bundle to use for TLS/https verification.
Multiple credential sets can be specified by including an index in the environment variable names, e.g.
KLUCTL_REGISTRY_1_HOST=host.org, KLUCTL_REGISTRY_1_USERNAME=my-user and KLUCTL_REGISTRY_1_PASSWORD=my-password will apply
the given credential to all registries with the host host.org, while KLUCTL_REGISTRY_2_HOST=other.org,
KLUCTL_REGISTRY_2_USERNAME=my-other-user and KLUCTL_REGISTRY_2_PASSWORD=my-other-password will apply the other credentials
to the other.org registry.
Credentials when using the kluctl-controller
In case you want to use the same Kluctl deployment via the kluctl-controller, you have to
configure OCI credentials via spec.credentials.
1.5.6 - SOPS Integration
Kluctl integrates natively with SOPS. Kluctl is able to decrypt all resources referenced by Kustomize deployment items (including simple deployments). In addition, Kluctl will also decrypt all variable sources of the types file and git.
Kluctl assumes that you have setup sops as usual so that it knows how to decrypt these files.
Only encrypting Secrets’s data
To only encrypt the data and stringData fields of Kubernetes secrets, use a .sops.yaml configuration file that
encrypted_regex to filter encrypted fields:
creation_rules:
- path_regex: .*.yaml
encrypted_regex: ^(data|stringData)$
Combining templating and SOPS
As an alternative, you can split secret values and the resulting Kubernetes resources into two different places and then use templating to use the secret values wherever needed. Example:
Write the following content into secrets/my-secrets.yaml:
secrets:
mySecret: secret-value
And encrypt it with SOPS:
$ sops -e -i secrets/my-secrets.yaml
Add this variables source to one of your deployments:
vars:
- file: secrets/my-secrets.yaml
deployments:
- ...
Then, in one of your deployment items define the following Secret:
apiVersion: v1
kind: Secret
metadata:
name: my-secret
namespace: default
stringData:
secret: "{{ secrets.mySecret }}"
1.5.7 - Hooks
Kluctl supports hooks in a similar fashion as known from Helm Charts. Hooks are executed/deployed before and/or after the actual deployment of a kustomize deployment.
To mark a resource as a hook, add the kluctl.io/hook annotation to a resource. The value of the annotation must be
a comma separated list of hook names. Possible value are described in the next chapter.
Hook types
| Hook Type | Description |
|---|---|
| pre-deploy-initial | Executed right before the initial deployment is performed. |
| post-deploy-initial | Executed right after the initial deployment is performed. |
| pre-deploy-upgrade | Executed right before a non-initial deployment is performed. |
| post-deploy-upgrade | Executed right after a non-initial deployment is performed. |
| pre-deploy | Executed right before any (initial and non-initial) deployment is performed. |
| post-deploy | Executed right after any (initial and non-initial) deployment is performed. |
A deployment is considered to be an “initial” deployment if none of the resources related to the current kustomize deployment are found on the cluster at the time of deployment.
If you need to execute hooks for every deployment, independent of its “initial” state, use
pre-deploy-initial,pre-deploy to indicate that it should be executed all the time.
Hook deletion
Hook resources are by default deleted right before creation (if they already existed before). This behavior can be
changed by setting the kluctl.io/hook-delete-policy to a comma separated list of the following values:
| Policy | Description |
|---|---|
| before-hook-creation | The default behavior, which means that the hook resource is deleted right before (re-)creation. |
| hook-succeeded | Delete the hook resource directly after it got “ready” |
| hook-failed | Delete the hook resource when it failed to get “ready” |
Hook readiness
After each deployment/execution of the hooks that belong to a deployment stage (before/after deployment), kluctl waits for the hook resources to become “ready”. Readiness is defined here.
It is possible to disable waiting for hook readiness by setting the annotation kluctl.io/hook-wait to “false”.
Hook Annotations
More control over hook behavior can be configured using additional annotations as described in annotations/hooks
1.5.8 - Readiness
There are multiple places where kluctl can wait for “readiness” of resources, e.g. for hooks or when waitReadiness is
specified on a deployment item. Readiness depends on the resource kind, e.g. for a Job, kluctl would wait until it
finishes successfully.
Control via Annotations
Multiple annotations control the behaviour when waiting for readiness of resources. These are the following annoations:
1.5.9 - Tags
Every kustomize deployment has a set of tags assigned to it. These tags are defined in multiple places, which is
documented in deployment.yaml. Look for the tags field, which is available in multiple places per
deployment project.
Tags are useful when only one or more specific kustomize deployments need to be deployed or deleted.
Default tags
deployment items in deployment projects can have an optional list of tags assigned.
If this list is completely omitted, one single entry is added by default. This single entry equals to the last element
of the path in the deployments entry.
Consider the following example:
deployments:
- path: nginx
- path: some/subdir
In this example, two kustomize deployments are defined. The first would get the tag nginx while the second
would get the tag subdir.
In most cases this heuristic is enough to get proper tags with which you can work. It might however lead to strange
or even conflicting tags (e.g. subdir is really a bad tag), in which case you’d have to explicitly set tags.
Tag inheritance
Deployment projects and deployments items inherit the tags of their parents. For example, if a deployment project
has a tags property defined, all deployments entries would
inherit all these tags. Also, the sub-deployment projects included via deployment items of type
include inherit the tags of the deployment project. These included sub-deployments also
inherit the tags specified by the deployment item itself.
Consider the following example deployment.yaml:
deployments:
- include: sub-deployment1
tags:
- tag1
- tag2
- include: sub-deployment2
tags:
- tag3
- tag4
- include: subdir/subsub
Any kustomize deployment found in sub-deployment1 would now inherit tag1 and tag2. If sub-deployment1 performs
any further includes, these would also inherit these two tags. Inheriting is additive and recursive.
The last sub-deployment project in the example is subject to the same default-tags logic as described
in Default tags, meaning that it will get the default tag subsub.
Deploying with tag inclusion/exclusion
Special care needs to be taken when trying to deploy only a specific part of your deployment which requires some base resources to be deployed as well.
Imagine a large deployment is able to deploy 10 applications, but you only want to deploy one of them. When using tags
to achieve this, there might be some base resources (e.g. Namespaces) which are needed no matter if everything or just
this single application is deployed. In that case, you’d need to set alwaysDeploy
to true.
Deleting with tag inclusion/exclusion
Also, in most cases, even more special care has to be taken for the same types of resources as decribed before.
Imagine a kustomize deployment being responsible for namespaces deployments. If you now want to delete everything except
deployments that have the persistency tag assigned, the exclusion logic would NOT exclude deletion of the namespace.
This would ultimately lead to everything being deleted, and the exclusion tag having no effect.
In such a case, you’d need to set skipDeleteIfTags to true as well.
In most cases, setting alwaysDeploy to true also requires setting skipDeleteIfTags to true.
1.5.10 - Annotations
1.5.10.1 - All resources
The following annotations control the behavior of the deploy and related commands.
Control deploy behavior
The following annotations control deploy behavior, especially in regard to conflict resolution.
kluctl.io/ignore
If set to “true”, the resource is completely ignored by Kluctl. This is equivalent to the resource not existing in your project.
This however means that if it was deployed in the past and then later kluctl.io/ignore is set to “true”, the resource
will be treated as orphan (which will cause deletion on prune). To avoid this, also set kluctl.io/skip-delete to “true”.
kluctl.io/delete
If set to “true”, the resource will be deleted at deployment time. Kluctl will not emit an error in case the resource does not exist. A resource with this annotation does not have to be complete/valid as it is never sent to the Kubernetes api server.
kluctl.io/force-apply
If set to “true”, the whole resource will be force-applied, meaning that all fields will be overwritten in case of field manager conflicts.
As an alternative, conflict resolution can be controlled via conflictResolution.
kluctl.io/force-apply-field
Specifies a JSON Path for fields that should be force-applied. Matching fields will be overwritten in case of field manager conflicts.
If more than one field needs to be specified, add -xxx to the annotation key, where xxx is an arbitrary number.
As an alternative, conflict resolution can be controlled via conflictResolution.
kluctl.io/force-apply-manager
Specifies a regex for managers that should be force-applied. Fields with matching managers will be overwritten in case of field manager conflicts.
If more than one field needs to be specified, add -xxx to the annotation key, where xxx is an arbitrary number.
As an alternative, conflict resolution can be controlled via conflictResolution.
kluctl.io/ignore-conflicts
If set to “true”, all object fields are going to be ignored when conflicts arise. This effectively disables the warnings that are shown when field ownership is lost.
As an alternative, conflict resolution can be controlled via conflictResolution.
kluctl.io/ignore-conflicts-field
Specifies a JSON Path for fields that should be ignored when conflicts arise. This effectively disables the warnings that are shown when field ownership is lost.
If more than one field needs to be specified, add -xxx to the annotation key, where xxx is an arbitrary number.
As an alternative, conflict resolution can be controlled via conflictResolution.
kluctl.io/ignore-conflicts-manager
Specifies a regex for field managers that should be ignored when conflicts arise. This effectively disables the warnings that are shown when field ownership is lost.
If more than one manager needs to be specified, add -xxx to the annotation key, where xxx is an arbitrary number.
As an alternative, conflict resolution can be controlled via conflictResolution.
kluctl.io/wait-readiness
If set to true, kluctl will wait for readiness of this object. Readiness is defined
the same as in hook readiness. Waiting happens after all resources from the parent
deployment item have been applied.
kluctl.io/is-ready
If set to true, kluctl will always consider this object as ready. If set to false,
kluctl will always consider this object as not ready. If omitted, kluctl will perform normal readiness checks.
This annotation is useful if you need to introduce externalized readiness determination, e.g. inside a non-hook Pod
that can annotate an object that something got ready.
Control deletion/pruning
The following annotations control how delete/prune is behaving.
kluctl.io/skip-delete
If set to “true”, the annotated resource will not be deleted when delete or prune is called.
kluctl.io/skip-delete-if-tags
If set to “true”, the annotated resource will not be deleted when delete or prune is called and inclusion/exclusion tags are used at the same time.
This tag is especially useful and required on resources that would otherwise cause cascaded deletions of resources that do not match the specified inclusion/exclusion tags. Namespaces are the most prominent example of such resources, as they most likely don’t match exclusion tags, but cascaded deletion would still cause deletion of the excluded resources.
kluctl.io/force-managed
If set to “true”, Kluctl will always treat the annotated resource as being managed by Kluctl, meaning that it will
consider it for deletion and pruning even if a foreign field manager resets/removes the Kluctl field manager or if
foreign controllers add ownerReferences even though they do not really own the resources.
Control diff behavior
The following annotations control how diffs are performed.
kluctl.io/diff-name
This annotation will override the name of the object when looking for the in-cluster version of an object used for diffs. This is useful when you are forced to use new names for the same objects whenever the content changes, e.g. for all kinds of immutable resource types.
Example (filename job.yaml):
apiVersion: batch/v1
kind: Job
metadata:
name: myjob-{{ load_sha256("job.yaml", 6) }}
annotations:
kluctl.io/diff-name: myjob
spec:
template:
spec:
containers:
- name: hello
image: busybox
command: ["sh", "-c", "echo hello"]
restartPolicy: Never
Without the kluctl.io/diff-name annotation, any change to the job.yaml would be treated as a new object in resulting
diffs from various commands. This is due to the inclusion of the file hash in the job name. This would make it very hard
to figure out what exactly changed in an object.
With the kluctl.io/diff-name annotation, kluctl will pick an existing job from the cluster with the same diff-name
and use it for the diff, making it a lot easier to analyze changes. If multiple objects match, the one with the youngest
creationTimestamp is chosen.
Please note that this will not cause old objects (with the same diff-name) to be prunes. You still have to regularely prune the deployment.
kluctl.io/ignore-diff
If set to “true”, the whole resource will be ignored while calculating diffs.
kluctl.io/ignore-diff-field
Specifies a JSON Path for fields that should be ignored while calculating diffs.
If more than one field needs to be specified, add -xxx to the annotation key, where xxx is an arbitrary number.
kluctl.io/ignore-diff-field-regex
Same as kluctl.io/ignore-diff-field but specifying a regular expressions instead of a JSON Path.
If more than one field needs to be specified, add -xxx to the annotation key, where xxx is an arbitrary number.
1.5.10.2 - Hooks
The following annotations control hook execution
See hooks for more details.
kluctl.io/hook
Declares a resource to be a hook, which is deployed/executed as described in hooks. The value of the annotation determines when the hook is deployed/executed.
kluctl.io/hook-weight
Specifies a weight for the hook, used to determine deployment/execution order. For resources with the same kluctl.io/hook annotation, hooks are executed in ascending order based on hook-weight.
kluctl.io/hook-delete-policy
Defines when to delete the hook resource.
kluctl.io/hook-wait
Defines whether kluctl should wait for hook-completion. It defaults to true and can be manually set to false.
1.5.10.3 - Validation
The following annotations influence the validate command.
validate-result.kluctl.io/xxx
If this annotation is found on a resource that is checked while validation, the key and the value of the annotation are added to the validation result, which is then returned by the validate command.
The annotation key is dynamic, meaning that all annotations that begin with validate-result.kluctl.io/ are taken
into account.
kluctl.io/validate-ignore
If this annotation is set to true, the object will be ignored while kluctl validate is run.
1.5.10.4 - Kustomize
Even though the kustomization.yaml from Kustomize deployments are not really Kubernetes resources (as they are not
really deployed), they have the same structure as Kubernetes resources. This also means that the kustomization.yaml
can define metadata and annotations. Through these annotations, additional behavior on the deployment can be controlled.
Example:
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
metadata:
annotations:
kluctl.io/barrier: "true"
kluctl.io/wait-readiness: "true"
resources:
- deployment.yaml
kluctl.io/barrier
If set to true, kluctl will wait for all previous objects to be applied (but not necessarily ready). This has the
same effect as barrier from deployment projects.
kluctl.io/wait-readiness
If set to true, kluctl will wait for readiness of all objects from this kustomization project. Readiness is defined
the same as in hook readiness. Waiting happens after all resources from the current
deployment item have been applied.
1.6 - Templating
kluctl uses a Jinja2 Templating engine to pre-process/render every involved configuration file and resource before actually interpreting it. Only files that are explicitly excluded via .templateignore files are not rendered via Jinja2.
Generally, everything that is possible with Jinja2 is possible in kluctl configuration/resources. Please read into the Jinja2 documentation to understand what exactly is possible and how to use it.
.templateignore
In some cases it is required to exclude specific files from templating, for example when the contents conflict with
the used template engine (e.g. Go templates conflict with Jinja2 and cause errors). In such cases, you can place
a .templateignore beside the excluded files or into a parent folder of it. The contents/format of the .templateignore
file is the same as you would use in a .gitignore file.
Includes and imports
Standard Jinja2 includes and imports can be used in all templates.
The path given to include/import is searched in the directory of the root template and all it’s parent directories up until the project root. Please note that the search path is not altered in included templates, meaning that it will always search in the same directories even if an include happens inside a file that was included as well.
To include/import a file relative to the currently rendered file (which is not necessarily the root template), prefix
the path with ./, e.g. use {% include "./my-relative-file.j2" %}".
Macros
Jinja2 macros are fully supported. When writing
macros that produce yaml resources, you must use the --- yaml separator in case you want to produce multiple resources
in one go.
Why no Go Templating
kluctl started as a python project and was then migrated to be a Go project. In the python world, Jinja2 is the obvious choice when it comes to templating. In the Go world, of course Go Templates would be the first choice.
When the migration to Go was performed, it was a conscious and opinionated decision to stick with Jinja2 templating. The reason is that I (@codablock) believe that Go Templates are hard to read and write and at the same time quite limited in their features (without extensive work). It never felt natural to write Go Templates.
This “feeling” was confirmed by multiple users of kluctl when it started and users described as “relieving” to not be forced to use Go Templates.
The above is my personal experience and opinion. I’m still quite open for contributions in regard to Go Templating support, as long as Jinja2 support is kept.
1.6.1 - Predefined Variables
There are multiple variables available which are pre-defined by kluctl. These are:
args
This is a dictionary of arguments given via command line. It contains every argument defined in deployment args.
target
This is the target definition of the currently processed target. It contains all values found in the
target definition, for example target.name.
images
This global object provides the dynamic images features described in images.
1.6.2 - Variable Sources
There are multiple places in deployment projects (deployment.yaml) where additional variables can be loaded into future Jinja2 contexts.
The first place where vars can be specified is the deployment root, as documented here. These vars are visible for all deployments inside the deployment project, including sub-deployments from includes.
The second place to specify variables is in the deployment items, as documented here.
The variables loaded for each entry in vars are not available inside the deployment.yaml file itself.
However, each entry in vars can use all variables defined before that specific entry is processed. Consider the
following example.
vars:
- file: vars1.yaml
- file: vars2.yaml
- file: optional-vars.yaml
ignoreMissing: true
- file: default-vars.yaml
noOverride: true
- file: vars3.yaml
when: some.var == "value"
- file: vars3.yaml
sensitive: true
- file: vars4.yaml
targetPath: my.target.path
vars2.yaml can now use variables that are defined in vars1.yaml. A special case is the use of previously defined
variables inside values vars sources. Please see the documentation of values for details.
At all times, variables defined by parents of the current sub-deployment project can be used in the current vars source.
The following properties can be set on all variable sources:
ignoreMissing
Each variable source can have the optional field ignoreMissing set to true, causing Kluctl to ignore if the source
can not be found.
noOverride
When specifying noOverride: true, Kluctl will not override variables from the previously loaded variables. This is
useful if you want to load default values for variables.
when
Variables can also be loaded conditionally by specifying a condition via when: <condition>. The condition must be in
the same format as described in conditional deployment items
sensitive
Specifying sensitive: true causes the Webui to redact the underlying variables for non-admin users. This will be set
to true by default for all variable sources that usually load sensitive data, including sops encrypted files and
Kubernetes secrets.
targetPath
Specifies a JSON path to be used as the target path in the new templating context.
Only simple paths are supported that do not contain wildcards or lists.
For some variable sources, targetPath will become mandatory when the resulting variable is not a dictionary.
It is also mandatory when multidoc is set to true.
Consider the following example:
# file: deployment.yaml
vars:
- file: vars1.yaml
targetPath: myvars
# file: vars1.yaml
var1: test
This will make the variables found in vars1.yaml accessible via {{ myvars.xxx }}.
multidoc
When set to true, the vars source’s underlying yaml document is treated as a yaml multidoc and the resulting variable
will be an array.
Using multidoc also requires you to set targetPath.
Consider the following example.
# file: deployment.yaml
vars:
- file: vars1.yaml
multidoc: true
targetPath: myvars
# file: vars1.yaml
---
var1: test1
---
var1: test2
---
var1: test3
This will load all documents from vars1.yaml, separated by --- and stored in the list myvars. The variables are
then accessible via {{ myvars[x].var1 }}.
Standard Jinja2 for loops can also be used with the
documents loaded in myvars.
Without multidoc: true, vars1.yaml would be loaded as a single document, stored in myvars. This means that only
the first document is loaded while the rest is discarded.
Variable source types
Different types of vars entries are possible:
file
This loads variables from a yaml file. Assume the following yaml file with the name vars1.yaml:
my_vars:
a: 1
b: "b"
c:
- l1
- l2
This file can be loaded via:
vars:
- file: vars1.yaml
After which all included deployments and sub-deployments can use the jinja2 variables from vars1.yaml.
Kluctl also supports variable files encrypted with SOPS. See the sops integration integration for more details.
values
An inline definition of variables. Example:
vars:
- values:
a: 1
b: c
These variables can then be used in all deployments and sub-deployments.
In case you need to use variables defined in previous vars sources, the values var source needs some special handling
in regard to templating. It’s important to understand that the deployment project is rendered BEFORE any vars source
processing is performed, which means that it will fail to render when you use previously defined variables in a values
vars source. To still use previously defined variables, surround the values vars source with {% raw %} and {% endraw %}.
In addition, the template expressions must be wrapped with ", as otherwise the loading of the deployment project
will fail shortly after rendering due to YAML parsing errors.
vars:
- values:
a: 1
b: c
{% raw %}
- values:
c: "{{ a }}"
{% endraw %}
An alternative syntax is to use a template expression that itself outputs a template expression:
vars:
- values:
a: 1
b: c
- values:
c: {{ '{{ a }}' }}
The advantage of the second method is that the type (number) of a is preserved, while the first method would convert
it into a string.
git
This loads variables from a file inside a git repository. Example:
vars:
- git:
url: ssh://git@github.com/example/repo.git
ref:
branch: my-branch
path: path/to/vars.yaml
The ref field has the same format at found in Git includes
Kluctl also supports variable files encrypted with SOPS. See the sops integration integration for more details.
gitFiles
This loads multiple branches/tags and its contents from a git repository. The branches/tags can be filtered via regex
and the files to load can be filtered via globs. Files can also be parsed and interpreted as yaml. Providing
targrtPath is mandatory for this variables source.
Example:
vars:
- gitFiles:
url: ssh://git@github.com/example/repo.git
ref:
branch: preview-env-.*
files:
- glob: preview-info.yaml
parseYaml: true
targetPath: previewEnvs
The following fields are supported for gitFiles.
url
Specified the Git url.
ref
Specifies the ref to match. The ref field has the same format at found in Git includes, with the addition that branches and tags can specify regular expressions.
files
Specifies a list of file filters. Each entry can have the following fields:
| field | required | description |
|---|---|---|
| glob | yes | Specifies the globbing pattern to test files against. / must be used as separator, even on Windows. |
| render | no | If set to true, Kluctl will render the content of matching files with the current context (excluding the currently loaded gitFiles. |
| parseYaml | no | If set to true, Kluctl will parse and interpret the content of matching files as YAML.The result is stored in the parsed field of the resulting file dict.Parsing happend after rendering (if render: true is used). |
| yamlMultiDoc | no | If set to true, Kluctl will treat the content of matching files as multi-document YAML file. |
gitFiles result
The above example will put the result into the variable previewEnvs. The result is a list of matching branches/tags with each entry
having the following form:
previewEnvs:
- ref:
branch: preview-env-1
refStr: refs/heads/preview-env-1
files:
- path: preview-info.yaml
size: 1234
content: |
some:
arbitrary:
yamlContent: 42
parsed:
some:
arbitrary:
yamlContent: 42
# this is a copy of the original `gitFiles.files` entry that caused this match
file:
glob: preview-info.yaml
parseYaml: true
# this is a flat dict with each entry being a copy of what is found in `files` for that same entry
# it is indexed by the relative path of each file
filesByPath:
preview-info.yaml:
path: preview-info.yaml
content: ...
dir1/sub-dir/file.yaml:
path: dir1/sub-dir/file.yaml
content: ...
# this is a nested dict that follows the directory structure
filesTree:
preview-info.yaml:
path: preview-info.yaml
content: ...
dir1:
sub-dir:
file.yaml:
path: dir1/sub-dir/file.yaml
content: ...
- ref:
branch: preview-env-2
...
Each file entry, as found in files, filesByPath and filesTree has the following fields:
| field | description |
|---|---|
| file | This is a copy of the files entry from gitFiles that caused the match. |
| path | The relative path inside the git repository. |
| size | The size of the file. If the file is encrypted, this specifies the size of the unencrypted content. |
| content | The content of the file. If the original file is encrypted, the content will contain the unencrypted content. If render: true was specified, the content will be the rendered content. |
| parsed | If parsed: true was specified, this field will contain the parsed content of the file. |
clusterConfigMap
Loads a configmap from the target’s cluster and loads the specified key’s value into the templating context. The value
is treated and loaded as YAML and thus can either be a simple value or a complex nested structure. In case of a simple
value (e.g. a number), you must also specify targetPath.
The referred ConfigMap must already exist while the Kluctl project is loaded, meaning that it is not possible to use a ConfigMap that is deployed as part of the Kluctl project itself.
Assume the following ConfigMap to be already deployed to the target cluster:
apiVersion: v1
kind: ConfigMap
metadata:
name: my-vars
namespace: my-namespace
data:
vars: |
a: 1
b: "b"
c:
- l1
- l2
This ConfigMap can be loaded via:
vars:
- clusterConfigMap:
name: my-vars
namespace: my-namespace
key: vars
The following example uses a simple value:
apiVersion: v1
kind: ConfigMap
metadata:
name: my-vars
namespace: my-namespace
data:
value: 123
This ConfigMap can be loaded via:
vars:
- clusterConfigMap:
name: my-vars
namespace: my-namespace
key: value
targetPath: deep.nested.path
clusterSecret
Same as clusterConfigMap, but for secrets.
clusterObject
Retrieves an arbitrary Kubernetes object from the target’s cluster and loads the specified content under path into the
templating context. The content can either be interpreted as is or interpreted and loaded as yaml text. In both cases,
rendering with the current context (without the newly introduced variables) can also be enabled.
targetPath must also be specified to configure under which sub-keys the new variables should be loaded.
The referred Kubernetes object must already exist while the Kluctl project is loaded, meaning that it is not possible to use
an object that is deployed as part of the Kluctl project itself. The exception to this is when you use ignoreMissing: true
and properly handle the missing case inside your templating (an example can be found further down).
Objects can either be referred to by name or by labels. In case of labels, Kluctl assumes that only a single object
matches. If multiple object are expected to match, list: true must also be passed, in which case the result loaded
into targetPath will be a list of objects instead of a single object.
Assume the following object to be already deployed to the target cluster:
apiVersion: some.group/v1
kind: SomeObject
metadata:
name: my-object
namespace: my-namespace
spec:
...
status:
my-status: all-good
This object can be loaded via:
vars:
- clusterObject:
kind: SomeObject
name: my-object
namespace: my-namespace
path: status
targetPath: my.custom.object.status
The following properties are supported for clusterObject sources:
kind (required)
The object kind. Kluctl will try to find the matching Kubernetes resource for this kind, which might either be a native
API resource or a custom resource. If multiple resources match, apiVersion must also be specified.
apiVersion (optional)
The apiVersion of the object. This field is only required if kind is not enough to identify the underlying API resource.
namespace (required)
The namespace from which to load the object.
name (optional)
The name of the object. If specified, the object with the given name must exist (ignoreMissing: true can override this).
Can be omitted when labels is specified.
labels (optional)
Specifies one or multiple labels to match. If specified, name is not allowed.
By default, assumes and requires (unless ignoreMissing: true is set) that only one object matches. If multiple objects
are assumed to match, set list: true as well, in which case the result will be a list as well.
list (optional)
If set to true, the result will be a list with one or more elements.
path (required)
Specifies a JSON path to be used to load a sub-key from the matching object(s).
Use $ to load the whole object. To load a single field, use something like status.my.field. To load a whole
sub-dict/sub-object or sub-list, use something like status.conditions.
The specified JSON path is only allowed to result in a single match.
render (optional)
If set to true, Kluctl will render the resulting object(s) with the current templating context (excluding the newly
loaded variables). Rendering happens on the values of individual fields of the resulting object(s). When parseYaml: true
is specified as well, rendering happens before parsing the YAML string.
parseYaml (optional)
Instructs Kluctl to treat the value found at path as a YAML string. The value must be of type string. Kluctl will parse
the string as YAML and use the resulting YAML value (which can be a simple int/float/bool or a complex list/dict) as the
result and store it in targetPath. When render: true is specified as well, the YAML string is rendered before parsing
happens.
http
The http variables source allows to load variables from an arbitrary HTTP resource by performing a GET (or any other configured HTTP method) on the URL. Example:
vars:
- http:
url: https://example.com/path/to/my/vars
The above source will load a variables file from the given URL. The file is expected to be in yaml or json format.
The following additional properties are supported for http sources:
method
Specifies the HTTP method to be used when requesting the given resource. Defaults to GET.
body
The body to send along with the request. If not specified, nothing is sent.
headers
A map of key/values pairs representing the header entries to be added to the request. If not specified, nothing is added.
jsonPath
Can be used to select a nested element from the yaml/json document returned by the HTTP request. This is useful in case some REST api is used which does not directly return the variables file. Example:
vars:
- http:
url: https://example.com/path/to/my/vars
jsonPath: $[0].data
The above example would successfully use the following json document as variables source:
[{"data": {"vars": {"var1": "value1"}}}]
Authentication
Kluctl currently supports BASIC and NTLM authentication. It will prompt for credentials when needed.
awsSecretsManager
AWS Secrets Manager integration. Loads a variables YAML from an AWS Secrets Manager secret. The secret can either be specified via an ARN or via a secretName and region combination. An existing AWS config profile can also be specified.
The secrets stored in AWS Secrets manager must contain a valid yaml or json file.
Example using an ARN:
vars:
- awsSecretsManager:
secretName: arn:aws:secretsmanager:eu-central-1:12345678:secret:secret-name-XYZ
profile: my-prod-profile
Example using a secret name and region:
vars:
- awsSecretsManager:
secretName: secret-name
region: eu-central-1
profile: my-prod-profile
The advantage of the latter is that the auto-generated suffix in the ARN (which might not be known at the time of writing the configuration) doesn’t have to be specified.
gcpSecretManager
Google Secret Manager integration. Loads a variables YAML from a Google Secrets
Manager secret. The secret name should be specified in projects/*/secrets/*/versions/* format.
The secrets stored in Google Secrets manager must contain a valid yaml or json file.
Example:
vars:
- gcpSecretManager:
secretName: "projects/my-project/secrets/secret/versions/latest"
It is recommended to use workload identity when you are using kluctl controller. You will need to annotate kluctl controller service account with service account name created in your google project:
args:
controller_service_account_annotations:
iam.gke.io/gcp-service-account: kluctl-controller@PROJECT-NAME.iam.gserviceaccount.com
substitute PROJECT-NAME with your real project name in google. Service account in your google project should have role roles/secretmanager.secretAccessor to access secrets.
To run kluctl locally with gcpSecretManager enabled refer to setting local development environment article.
azureKeyVault
Azure Key Vault integration. Loads a variables YAML from an Azure Key Vault.
Example
vars:
- azureKeyVault:
vaultUri: "https://example.vault.azure.net/"
secretName: kluctl
SDK azure-sdk-for-go supports az login
or Environment Variables
$ export AZURE_CLIENT_ID="__CLIENT_ID__"
$ export AZURE_CLIENT_SECRET="__CLIENT_SECRET__"
$ export AZURE_TENANT_ID="__TENANT_ID__"
$ export AZURE_SUBSCRIPTION_ID="__SUBSCRIPTION_ID__"
vault
Vault by HashiCorp with Tokens authentication integration. The address and the path to the secret can be configured. The implementation was tested with KV Secrets Engine.
Example using vault:
vars:
- vault:
address: http://localhost:8200
path: secret/data/simple
Before deploying please make sure that you have access to vault. You can do this for example by setting
the environment variable VAULT_TOKEN.
systemEnvVars
Load variables from environment variables. Children of systemEnvVars can be arbitrary yaml, e.g. dictionaries or lists.
The leaf values are used to get a value from the system environment.
Example:
vars:
- systemEnvVars:
var1: ENV_VAR_NAME1
someDict:
var2: ENV_VAR_NAME2
someList:
- var3: ENV_VAR_NAME3
The above example will make 3 variables available: var1, someDict.var2 and
someList[0].var3, each having the values of the environment variables specified by the leaf values.
All specified environment variables must be set before calling kluctl unless a default value is set. Default values
can be set by using the ENV_VAR_NAME:default-value form.
Example:
vars:
- systemEnvVars:
var1: ENV_VAR_NAME4:defaultValue
The above example will set the variable var1 to defaultValue in case ENV_VAR_NAME4 is not set.
All values retrieved from environment variables (or specified as default values) will be treated as YAML, meaning that integers and booleans will be treated as integers/booleans. If you want to enforce strings, encapsulate the values in quotes.
Example:
vars:
- systemEnvVars:
var1: ENV_VAR_NAME5:'true'
The above example will treat true as a string instead of a boolean. When the environment variable is set outside
kluctl, it should also contain the quotes. Please note that your shell might require escaping to properly pass quotes.
1.6.3 - Filters
In addition to the builtin Jinja2 filters, kluctl provides a few additional filters:
b64encode
Encodes the input value as base64. Example: {{ "test" | b64encode }} will result in dGVzdA==.
b64decode
Decodes an input base64 encoded string. Example {{ my.source.var | b64decode }}.
from_yaml
Parses a yaml string and returns an object. Please note that json is valid yaml, meaning that you can also use this filter to parse json.
to_yaml
Converts a variable/object into its yaml representation. Please note that in most cases the resulting string will not
be properly indented, which will require you to also use the indent filter. Example:
apiVersion: v1
kind: ConfigMap
metadata:
name: my-config
data:
config.yaml: |
{{ my_config | to_yaml | indent(4) }}
to_json
Same as to_yaml, but with json as output. Please note that json is always valid yaml, meaning that you can also use
to_json in yaml files. Consider the following example:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
template:
spec:
containers:
- name: c1
image: my-image
env: {{ my_list_of_env_entries | to_json }}
This would render json into a yaml file, which is still a valid yaml file. Compare this to how this would have to be
solved with to_yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
template:
spec:
containers:
- name: c1
image: my-image
env:
{{ my_list_of_env_entries | to_yaml | indent(10) }}
The required indention filter is the part that makes this error-prone and hard to maintain. Consider using to_json
whenever you can.
render
Same as the global render function, but deprecated now. render being a filter turned out to
not work well with local variables, as these are not accessible in filters. Please only use the global function.
sha256(digest_len)
Calculates the sha256 digest of the input string. Example:
{{ "some-string" | sha256 }}
digest_len is an optional parameter that allows to limit the length of the returned hex digest. Example:
{{ "some-string" | sha256(6) }}
slugify
Slugify a string based on python-slugify.
1.6.4 - Functions
In addition to the provided builtin global functions, kluctl also provides a few global functions:
load_template(file)
Loads the given file into memory, renders it with the current Jinja2 context and then returns it as a string. Example:
{% set a=load_template('file.yaml') %}
{{ a }}
load_template uses the same path searching rules as described in includes/imports.
Please note that there is a limitation in this (and other) functions in regard to loop variables. You can currently not use loop variables directly as they are not accessible inside Jinja2 extensions/filters. There is an open issue in that regard here. For a workaround, perform the same as in get_var.
load_sha256(file, digest_len)
Loads the given file into memory, renders it and calculates the sha256 hash of the result.
The filename given to load_sha256 is treated the same as in load_template. Recursive loading/calculating of hashes
is allowed and is solved by replacing load_sha256 invocations with currently loaded templates with dummy strings.
This also allows to calculate the hash of the currently rendered template, for example:
apiVersion: v1
kind: ConfigMap
metadata:
name: my-config-{{ load_sha256("configmap.yaml") }}
data:
digest_len is an optional parameter that allows to limit the length of the returned hex digest.
load_latest_git_commit(file, sha_len)
Loads the first parent git repository of the given file and returns the latest commit sha1 hash as a hex string.
The filename given to load_latest_git_commit is treated the same as in load_template and load_sha256.
apiVersion: v1
kind: ConfigMap
metadata:
name: my-config-{{ load_latest_git_commit("configmap.yaml") }}
data:
sha_len is an optional parameter that allows to limit the length of the returned hex digest.
load_base64(file, width)
Loads the given file into memory and returns the base64 representation of the binary data.
The width parameter is optional and causes load_base64 to wrap the base64 string into a multiline string.
The filename given to load_base64 is treated the same as in load_template.
This function is useful if you need to include binary data in your deployment. For example:
apiVersion: v1
kind: Secret
metadata:
name: my-secret
data:
binarySecret: "{{ load_base64("secret.bin") }}"
To use wrapped base64, use:
apiVersion: v1
kind: Secret
metadata:
name: my-secret
data:
binarySecret: |
"{{ load_base64("large-secret.bin") | indent(4) }}"
get_var(field_path, default)
Convenience method to navigate through the current context variables via a JSON Path. Let’s assume you currently have these variables defined (e.g. via vars):
my:
deep:
var: value
Then {{ get_var('my.deep.var', 'my-default') }} would return value.
When any of the elements inside the field path are non-existent, the given default value is returned instead.
The field_path parameter can also be a list of pathes, which are then tried one after the another, returning the first
result that gives a value that is not None. For example, {{ get_var(['non.existing.var', my.deep.var'], 'my-default') }}
would also return value.
Please note that there is a limitation in this (and other) functions in regard to loop variables. You can currently not use loop variables directly as they are not accessible inside Jinja2 global functions or filters. There is an open issue in that regard here. For a workaround, assign the loop variable to a local variable:
{% set list=[{x: "a"}, {x: "b"}, {x: "c"}] %}
{% for e in list %}
{% set e=e %} <-- this is the workaround
{{ get_var('e.x') }}
{% endfor %}
merge_dict(d1, d2)
Clones d1 and then recursively merges d2 into it and returns the result. Values inside d2 will override values in d1.
update_dict(d1, d2)
Same as merge_dict, but merging is performed in-place into d1.
raise(msg)
Raises a python exception with the given message. This causes the current command to abort.
render(template)
Renders the input string with the current Jinja2 context. Example:
{% set a="{{ my_var }}" %}
{{ render(a) }}
Please note that there is a limitation in this (and other) functions in regard to loop variables. You can currently not use loop variables directly as they are not accessible inside Jinja2 global functions or filters. There is an open issue in that regard here. For a workaround, perform the same as in get_var.
debug_print(msg)
Prints a line to stderr.
time.now()
Returns the current time. The returned object has the following members:
| member | description |
|---|---|
| t.as_timezone(tz) | Converts and returns the time t in the given timezone. Example:{{ time.now().as_timezone("Europe/Berlin") }} |
| t.weekday() | Returns the time’s weekday. 0 means Monday and 6 means Sunday. |
| t.hour() | Returns the time’s hour from 0-23. |
| t.minute() | Returns the time’s minute from 0-59. |
| t.second() | Returns the time’s second from 0-59. |
| t.nanosecond() | Returns the time’s nanosecond from 0-999999999. |
| t + delta | Adds a delta to t. Example: {{ time.now() + time.second * 10 }} |
| t - delta | Subtracts a delta from t. Example: {{ time.now() - time.second * 10 }} |
| t1 < t2 t1 >= t2 … | Time objects can be compared to other time objects. Example:{% if time.now() < time.parse_iso("2022-10-01T10:00") %}...{% endif %}All logical operators are supported. |
time.utcnow()
Returns the current time in UTC. The object has the same members as described in time.now().
time.parse_iso(iso_time_str)
Parse the given string and return a time object. The string must be in ISO time. The object has the same members as described in time.now().
time.second, time.minute, time.hour
Represents a time delta to be used with t + delta and t - delta. Example
{{ time.now() + time.minute * 10 }}
1.7 - Commands
kluctl offers a unified command line interface that allows to standardize all your deployments. Every project, no matter how different it is from other projects, is managed the same way.
You can always call kluctl --help or kluctl <command> --help for a help prompt.
Individual commands are documented in sub-sections.
1.7.1 - Common Arguments
A few sets of arguments are common between multiple commands. These arguments are still part of the command itself and must be placed after the command name.
Global arguments
These arguments are available for all commands.
Global arguments:
--cpu-profile string Enable CPU profiling and write the result to the given path
--debug Enable debug logging
--gops-agent Start gops agent in the background
--gops-agent-addr string Specify the address:port to use for the gops agent (default "127.0.0.1:0")
--no-color Disable colored output
--no-update-check Disable update check on startup
--use-system-python Use the system Python instead of the embedded Python.
Project arguments
These arguments are available for all commands that are based on a Kluctl project. They control where and how to load the kluctl project and deployment project.
Project arguments:
Define where and how to load the kluctl project and its components from.
-a, --arg stringArray Passes a template argument in the form of name=value. Nested args
can be set with the '-a my.nested.arg=value' syntax. Values are
interpreted as yaml values, meaning that 'true' and 'false' will
lead to boolean values and numbers will be treated as numbers. Use
quotes if you want these to be treated as strings. If the value
starts with @, it is treated as a file, meaning that the contents
of the file will be loaded and treated as yaml.
--args-from-file stringArray Loads a yaml file and makes it available as arguments, meaning that
they will be available thought the global 'args' variable.
--context string Overrides the context name specified in the target. If the selected
target does not specify a context or the no-name target is used,
--context will override the currently active context.
--git-cache-update-interval duration Specify the time to wait between git cache updates. Defaults to not
wait at all and always updating caches.
--kubeconfig existingfile Overrides the kubeconfig to use.
--local-git-group-override stringArray Same as --local-git-override, but for a whole group prefix instead
of a single repository. All repositories that have the given prefix
will be overridden with the given local path and the repository
suffix appended. For example,
'gitlab.com/some-org/sub-org=/local/path/to/my-forks' will override
all repositories below 'gitlab.com/some-org/sub-org/' with the
repositories found in '/local/path/to/my-forks'. It will however
only perform an override if the given repository actually exists
locally and otherwise revert to the actual (non-overridden) repository.
--local-git-override stringArray Specify a single repository local git override in the form of
'github.com/my-org/my-repo=/local/path/to/override'. This will
cause kluctl to not use git to clone for the specified repository
but instead use the local directory. This is useful in case you
need to test out changes in external git repositories without
pushing them. Repositories are specified as 'normalized repo keys',
which are in the format '<host>/<path>', meaning that no schema (no
git://) must be specified.
--local-oci-group-override stringArray Same as --local-git-group-override, but for OCI repositories.
--local-oci-override stringArray Same as --local-git-override, but for OCI repositories.
-c, --project-config existingfile Location of the .kluctl.yaml config file. Defaults to
$PROJECT/.kluctl.yaml
--project-dir existingdir Specify the project directory. Defaults to the current working
directory.
-t, --target string Target name to run command for. Target must exist in .kluctl.yaml.
-T, --target-name-override string Overrides the target name. If -t is used at the same time, then the
target will be looked up based on -t <name> and then renamed to the
value of -T. If no target is specified via -t, then the no-name
target is renamed to the value of -T.
--timeout duration Specify timeout for all operations, including loading of the
project, all external api calls and waiting for readiness. (default
10m0s)
Image arguments
These arguments are available on some target based commands.
They control image versions requested by images.get_image(...) calls.
Image arguments:
Control fixed images and update behaviour.
-F, --fixed-image stringArray Pin an image to a given version. Expects
'--fixed-image=image<:namespace:deployment:container>=result'
--fixed-images-file existingfile Use .yaml file to pin image versions. See output of list-images
sub-command or read the documentation for details about the output format
Inclusion/Exclusion arguments
These arguments are available for some target based commands. They control inclusion/exclusion based on tags and deployment item pathes.
Inclusion/Exclusion arguments:
Control inclusion/exclusion.
--exclude-deployment-dir stringArray Exclude deployment dir. The path must be relative to the root
deployment project. Exclusion has precedence over inclusion, same as
in --exclude-tag
-E, --exclude-tag stringArray Exclude deployments with given tag. Exclusion has precedence over
inclusion, meaning that explicitly excluded deployments will always
be excluded even if an inclusion rule would match the same deployment.
--include-deployment-dir stringArray Include deployment dir. The path must be relative to the root
deployment project.
-I, --include-tag stringArray Include deployments with given tag.
Command Results arguments
These arguments control how command results are stored.
Command Results:
Configure how command results are stored.
--command-result-namespace string Override the namespace to be used when writing command results. (default
"kluctl-results")
--force-write-command-result Force writing of command results, even if the command is run in dry-run mode.
--keep-command-results-count int Configure how many old command results to keep. (default 5)
--keep-validate-results-count int Configure how many old validate results to keep. (default 2)
--write-command-result Enable writing of command results into the cluster. This is enabled by
default. (default true)
Git arguments
These arguments mainly control authentication to Git repositories.
Git arguments:
Configure Git authentication.
--git-ca-file stringArray Specify CA bundle to use for https verification. Must be in the
form --git-ca-file=<registry>/<repo>=<filePath>.
--git-password stringArray Specify password to use for Git basic authentication. Must be in
the form --git-password=<host>/<path>=<password>.
--git-ssh-key-file stringArray Specify SSH key to use for Git authentication. Must be in the form
--git-ssh-key-file=<host>/<path>=<filePath>.
--git-ssh-known-hosts-file stringArray Specify known_hosts file to use for Git authentication. Must be in
the form --git-ssh-known-hosts-file=<host>/<path>=<filePath>.
--git-username stringArray Specify username to use for Git basic authentication. Must be in
the form --git-username=<host>/<path>=<username>.
All the arguments from above can also be passed via environment variables. For example:
# for http(s) username/password auth
export KLUCTL_GIT_0_HOST="github.com"
export KLUCTL_GIT_0_USERNAME="my-user"
export KLUCTL_GIT_0_PASSWORD="my-password"
# in case you have self-signed certs or other non-standard CAs
export KLUCTL_GIT_0_CA_BUNDLE="/path/to/ca/bundle"
# for ssh auth
export KLUCTL_GIT_1_HOST="gitlab.com"
export KLUCTL_GIT_1_SSH_KEY="/path/to/ssh/key"
# optionally specify path glob to limit this credentials set to only a defined set of repos (can also be used with http auth)
export KLUCTL_GIT_1_PATH="my-org/*"
In addition to the provided credentials, Kluctl will also try to use default Git authentication mechanisms like git credentials helpers, default SSH keys and SSH agents.
Helm arguments
These arguments mainly control authentication to Helm repositories.
Helm arguments:
Configure Helm authentication.
--helm-ca-file stringArray Specify ca bundle certificate to use for Helm Repository
authentication. Must be in the form
--helm-ca-file=<host>/<path>=<filePath>
--helm-cert-file stringArray Specify key to use for Helm Repository authentication. Must be
in the form --helm-cert-file=<host>/<path>=<filePath>
--helm-creds stringArray This is a shortcut to --helm-username and --helm-password.
Must be in the form
--helm-creds=<host>/<path>=<username>:<password>, which
specifies the username and password for the same repository.
--helm-insecure-skip-tls-verify stringArray Controls skipping of TLS verification. Must be in the form
--helm-insecure-skip-tls-verify=<host>/<path>
--helm-key-file stringArray Specify client certificate to use for Helm Repository
authentication. Must be in the form
--helm-key-file=<host>/<path>=<filePath>
--helm-password stringArray Specify password to use for Helm Repository authentication.
Must be in the form --helm-password=<host>/<path>=<password>
--helm-username stringArray Specify username to use for Helm Repository authentication.
Must be in the form --helm-username=<host>/<path>=<username>
All the arguments from above can also be passed via environment variables. For example:
# for http(s) username/password auth
export KLUCTL_HELM_0_HOST="gitlab.com"
export KLUCTL_HELM_0_USERNAME="my-user"
export KLUCTL_HELM_0_PASSWORD="my-password"
export KLUCTL_HELM_0_PATH="api/v4/projects/1111111/packages/helm/stable"
# in case you have self-signed certs or other non-standard CAs
export KLUCTL_HELM_0_CA_FILE="/path/to/ca/bundle"
...
Registry arguments
These arguments mainly control authentication to OCI based registries. This is used by the Helm integration and by the OCI includes integration.
Registry arguments:
Configure OCI registry authentication.
--registry-ca-file stringArray Specify CA bundle to use for https verification. Must be
in the form --registry-ca-file=<registry>/<repo>=<filePath>.
--registry-cert-file stringArray Specify certificate to use for OCI authentication. Must be
in the form --registry-cert-file=<registry>/<repo>=<filePath>.
--registry-creds stringArray This is a shortcut to --registry-username,
--registry-password and --registry-token. It can be
specified in two different forms. The first one is
--registry-creds=<registry>/<repo>=<username>:<password>,
which specifies the username and password for the same
registry. The second form is
--registry-creds=<registry>/<repo>=<token>, which
specifies a JWT token for the specified registry.
--registry-identity-token stringArray Specify identity token to use for OCI authentication. Must
be in the form
--registry-identity-token=<registry>/<repo>=<identity-token>.
--registry-insecure-skip-tls-verify stringArray Controls skipping of TLS verification. Must be in the form
--registry-insecure-skip-tls-verify=<registry>/<repo>.
--registry-key-file stringArray Specify key to use for OCI authentication. Must be in the
form --registry-key-file=<registry>/<repo>=<filePath>.
--registry-password stringArray Specify password to use for OCI authentication. Must be in
the form --registry-password=<registry>/<repo>=<password>.
--registry-plain-http stringArray Forces the use of http (no TLS). Must be in the form
--registry-plain-http=<registry>/<repo>.
--registry-token stringArray Specify registry token to use for OCI authentication. Must
be in the form --registry-token=<registry>/<repo>=<token>.
--registry-username stringArray Specify username to use for OCI authentication. Must be in
the form --registry-username=<registry>/<repo>=<username>.
All the arguments from above can also be passed via environment variables. For example:
# for http(s) username/password auth
export KLUCTL_REGISTRY_0_HOST="docker.io"
export KLUCTL_REGISTRY_0_USERNAME="my-user"
export KLUCTL_REGISTRY_0_PASSWORD="my-password"
export KLUCTL_REGISTRY_0_PATH="my-org/*"
# in case you have self-signed certs or other non-standard CAs
export KLUCTL_REGISTRY_0_CA_FILE="/path/to/ca/bundle"
...
1.7.2 - Environment Variables
In addition to arguments, Kluctl can be controlled via a set of environment variables.
Environment variables as arguments
All options/arguments accepted by kluctl can also be specified via environment variables. The name of the environment
variables always start with KLUCTL_ and end with the option/argument in uppercase and dashes replaced with
underscores. As an example, --dry-run can also be specified with the environment variable
KLUCTL_DRY_RUN=true.
If an argument needs to be specified multiple times through environment variables, indexed can be appended to the
names of the environment variables, e.g. KLUCTL_ARG_0=name1=value1 and KLUCTL_ARG_1=name2=value2.
Additional environment variables
A few additional environment variables are supported which do not belong to an option/argument. These are:
KLUCTL_SSH_DISABLE_STRICT_HOST_KEY_CHECKING. Disable ssh host key checking when accessing git repositories.
1.7.3 - gitops deploy
Command
Usage: kluctl gitops deploy [flags]
Trigger a GitOps deployment This command will trigger an existing KluctlDeployment to perform a reconciliation loop with a forced deployment. It does this by setting the annotation ‘kluctl.io/request-deploy’ to the current time.
You can override many deployment relevant fields, see the list of command flags for details.
Arguments
The following arguments are available:
GitOps arguments:
Specify gitops flags.
--context string Override the context to use.
--controller-namespace string The namespace where the controller runs in. (default "kluctl-system")
--kubeconfig existingfile Overrides the kubeconfig to use.
-l, --label-selector string If specified, KluctlDeployments are searched and filtered by this label
selector.
--local-source-override-port int Specifies the local port to which the source-override client should
connect to when running the controller locally.
--name string Specifies the name of the KluctlDeployment.
-n, --namespace string Specifies the namespace of the KluctlDeployment. If omitted, the current
namespace from your kubeconfig is used.
Misc arguments:
Command specific arguments.
--no-obfuscate Disable obfuscation of sensitive/secret data
-o, --output-format stringArray Specify output format and target file, in the format 'format=path'. Format can
either be 'text' or 'yaml'. Can be specified multiple times. The actual format
for yaml is currently not documented and subject to change.
--short-output When using the 'text' output format (which is the default), only names of
changes objects are shown instead of showing all changes.
Command Results:
Configure how command results are stored.
--command-result-namespace string Override the namespace to be used when writing command results. (default
"kluctl-results")
Log arguments:
Configure logging.
--log-grouping-time duration Logs are by default grouped by time passed, meaning that they are printed in
batches to make reading them easier. This argument allows to modify the
grouping time. (default 1s)
--log-since duration Show logs since this time. (default 1m0s)
--log-time If enabled, adds timestamps to log lines
GitOps overrides:
Override settings for GitOps deployments.
--abort-on-error Abort deploying when an error occurs instead of trying the
remaining deployments
-a, --arg stringArray Passes a template argument in the form of name=value. Nested args
can be set with the '-a my.nested.arg=value' syntax. Values are
interpreted as yaml values, meaning that 'true' and 'false' will
lead to boolean values and numbers will be treated as numbers. Use
quotes if you want these to be treated as strings. If the value
starts with @, it is treated as a file, meaning that the contents
of the file will be loaded and treated as yaml.
--args-from-file stringArray Loads a yaml file and makes it available as arguments, meaning that
they will be available thought the global 'args' variable.
--dry-run Performs all kubernetes API calls in dry-run mode.
--exclude-deployment-dir stringArray Exclude deployment dir. The path must be relative to the root
deployment project. Exclusion has precedence over inclusion, same
as in --exclude-tag
-E, --exclude-tag stringArray Exclude deployments with given tag. Exclusion has precedence over
inclusion, meaning that explicitly excluded deployments will always
be excluded even if an inclusion rule would match the same deployment.
-F, --fixed-image stringArray Pin an image to a given version. Expects
'--fixed-image=image<:namespace:deployment:container>=result'
--fixed-images-file existingfile Use .yaml file to pin image versions. See output of list-images
sub-command or read the documentation for details about the output
format
--force-apply Force conflict resolution when applying. See documentation for details
--force-replace-on-error Same as --replace-on-error, but also try to delete and re-create
objects. See documentation for more details.
--include-deployment-dir stringArray Include deployment dir. The path must be relative to the root
deployment project.
-I, --include-tag stringArray Include deployments with given tag.
--local-git-group-override stringArray Same as --local-git-override, but for a whole group prefix instead
of a single repository. All repositories that have the given prefix
will be overridden with the given local path and the repository
suffix appended. For example,
'gitlab.com/some-org/sub-org=/local/path/to/my-forks' will override
all repositories below 'gitlab.com/some-org/sub-org/' with the
repositories found in '/local/path/to/my-forks'. It will however
only perform an override if the given repository actually exists
locally and otherwise revert to the actual (non-overridden) repository.
--local-git-override stringArray Specify a single repository local git override in the form of
'github.com/my-org/my-repo=/local/path/to/override'. This will
cause kluctl to not use git to clone for the specified repository
but instead use the local directory. This is useful in case you
need to test out changes in external git repositories without
pushing them. Repositories are specified as 'normalized repo keys',
which are in the format '<host>/<path>', meaning that no schema (no
git://) must be specified.
--local-oci-group-override stringArray Same as --local-git-group-override, but for OCI repositories.
--local-oci-override stringArray Same as --local-git-override, but for OCI repositories.
--no-wait Don't wait for objects readiness.
--prune Prune orphaned objects directly after deploying. See the help for
the 'prune' sub-command for details.
--replace-on-error When patching an object fails, try to replace it. See documentation
for more details.
-t, --target string Target name to run command for. Target must exist in .kluctl.yaml.
--target-context string Overrides the context name specified in the target. If the selected
target does not specify a context or the no-name target is used,
--context will override the currently active context.
-T, --target-name-override string Overrides the target name. If -t is used at the same time, then the
target will be looked up based on -t <name> and then renamed to the
value of -T. If no target is specified via -t, then the no-name
target is renamed to the value of -T.
1.7.4 - gitops diff
Command
Usage: kluctl gitops diff [flags]
Trigger a GitOps diff This command will trigger an existing KluctlDeployment to perform a reconciliation loop with a forced diff. It does this by setting the annotation ‘kluctl.io/request-diff’ to the current time.
You can override many deployment relevant fields, see the list of command flags for details.
Arguments
The following arguments are available:
GitOps arguments:
Specify gitops flags.
--context string Override the context to use.
--controller-namespace string The namespace where the controller runs in. (default "kluctl-system")
--kubeconfig existingfile Overrides the kubeconfig to use.
-l, --label-selector string If specified, KluctlDeployments are searched and filtered by this label
selector.
--local-source-override-port int Specifies the local port to which the source-override client should
connect to when running the controller locally.
--name string Specifies the name of the KluctlDeployment.
-n, --namespace string Specifies the namespace of the KluctlDeployment. If omitted, the current
namespace from your kubeconfig is used.
Misc arguments:
Command specific arguments.
--no-obfuscate Disable obfuscation of sensitive/secret data
-o, --output-format stringArray Specify output format and target file, in the format 'format=path'. Format can
either be 'text' or 'yaml'. Can be specified multiple times. The actual format
for yaml is currently not documented and subject to change.
--short-output When using the 'text' output format (which is the default), only names of
changes objects are shown instead of showing all changes.
Command Results:
Configure how command results are stored.
--command-result-namespace string Override the namespace to be used when writing command results. (default
"kluctl-results")
Log arguments:
Configure logging.
--log-grouping-time duration Logs are by default grouped by time passed, meaning that they are printed in
batches to make reading them easier. This argument allows to modify the
grouping time. (default 1s)
--log-since duration Show logs since this time. (default 1m0s)
--log-time If enabled, adds timestamps to log lines
GitOps overrides:
Override settings for GitOps deployments.
--abort-on-error Abort deploying when an error occurs instead of trying the
remaining deployments
-a, --arg stringArray Passes a template argument in the form of name=value. Nested args
can be set with the '-a my.nested.arg=value' syntax. Values are
interpreted as yaml values, meaning that 'true' and 'false' will
lead to boolean values and numbers will be treated as numbers. Use
quotes if you want these to be treated as strings. If the value
starts with @, it is treated as a file, meaning that the contents
of the file will be loaded and treated as yaml.
--args-from-file stringArray Loads a yaml file and makes it available as arguments, meaning that
they will be available thought the global 'args' variable.
--dry-run Performs all kubernetes API calls in dry-run mode.
--exclude-deployment-dir stringArray Exclude deployment dir. The path must be relative to the root
deployment project. Exclusion has precedence over inclusion, same
as in --exclude-tag
-E, --exclude-tag stringArray Exclude deployments with given tag. Exclusion has precedence over
inclusion, meaning that explicitly excluded deployments will always
be excluded even if an inclusion rule would match the same deployment.
-F, --fixed-image stringArray Pin an image to a given version. Expects
'--fixed-image=image<:namespace:deployment:container>=result'
--fixed-images-file existingfile Use .yaml file to pin image versions. See output of list-images
sub-command or read the documentation for details about the output
format
--force-apply Force conflict resolution when applying. See documentation for details
--force-replace-on-error Same as --replace-on-error, but also try to delete and re-create
objects. See documentation for more details.
--include-deployment-dir stringArray Include deployment dir. The path must be relative to the root
deployment project.
-I, --include-tag stringArray Include deployments with given tag.
--local-git-group-override stringArray Same as --local-git-override, but for a whole group prefix instead
of a single repository. All repositories that have the given prefix
will be overridden with the given local path and the repository
suffix appended. For example,
'gitlab.com/some-org/sub-org=/local/path/to/my-forks' will override
all repositories below 'gitlab.com/some-org/sub-org/' with the
repositories found in '/local/path/to/my-forks'. It will however
only perform an override if the given repository actually exists
locally and otherwise revert to the actual (non-overridden) repository.
--local-git-override stringArray Specify a single repository local git override in the form of
'github.com/my-org/my-repo=/local/path/to/override'. This will
cause kluctl to not use git to clone for the specified repository
but instead use the local directory. This is useful in case you
need to test out changes in external git repositories without
pushing them. Repositories are specified as 'normalized repo keys',
which are in the format '<host>/<path>', meaning that no schema (no
git://) must be specified.
--local-oci-group-override stringArray Same as --local-git-group-override, but for OCI repositories.
--local-oci-override stringArray Same as --local-git-override, but for OCI repositories.
--replace-on-error When patching an object fails, try to replace it. See documentation
for more details.
-t, --target string Target name to run command for. Target must exist in .kluctl.yaml.
--target-context string Overrides the context name specified in the target. If the selected
target does not specify a context or the no-name target is used,
--context will override the currently active context.
-T, --target-name-override string Overrides the target name. If -t is used at the same time, then the
target will be looked up based on -t <name> and then renamed to the
value of -T. If no target is specified via -t, then the no-name
target is renamed to the value of -T.
1.7.5 - controller install
Command
Usage: kluctl controller install [flags]
Install the Kluctl controller This command will install the kluctl-controller to the current Kubernetes clusters.
Arguments
The following sets of arguments are available:
In addition, the following arguments are available:
Misc arguments:
Command specific arguments.
--context string Override the context to use.
--dry-run Performs all kubernetes API calls in dry-run mode.
--kluctl-version string Specify the controller version to install.
-y, --yes Suppresses 'Are you sure?' questions and proceeds as if you would answer 'yes'.
1.7.6 - list-targets
Command
Usage: kluctl list-targets [flags]
Outputs a yaml list with all targets Outputs a yaml list with all targets
Arguments
The following arguments are available:
Misc arguments:
Command specific arguments.
--only-names If provided --only-names will only output
-o, --output stringArray Specify output target file. Can be specified multiple times
1.7.7 - controller run
Command
Usage: kluctl controller run [flags]
Run the Kluctl controller This command will run the Kluctl Controller. This is usually meant to be run inside a cluster and not from your local machine.
Arguments
The following arguments are available:
Misc arguments:
Command specific arguments.
--concurrency int Configures how many KluctlDeployments can be be reconciled
concurrently. (default 4)
--context string Override the context to use.
--controller-name string The controller name used for metrics and logs. (default
"kluctl-controller")
--controller-namespace string The namespace where the controller runs in. (default "kluctl-system")
--default-service-account string Default service account used for impersonation.
--dry-run Run all deployments in dryRun=true mode.
--health-probe-bind-address string The address the probe endpoint binds to. (default ":8081")
--kubeconfig string Override the kubeconfig to use.
--leader-elect Enable leader election for controller manager. Enabling this will
ensure there is only one active controller manager.
--metrics-bind-address string The address the metric endpoint binds to. (default ":8080")
--namespace string Specify the namespace to watch. If omitted, all namespaces are watched.
--source-override-bind-address string The address the source override manager endpoint binds to. (default
":8082")
1.7.8 - webui run
Command
Usage: kluctl webui run [flags]
Run the Kluctl Webui
Arguments
The following arguments are available:
Misc arguments:
Command specific arguments.
--all-contexts Use all Kubernetes contexts found in the kubeconfig.
--context stringArray List of kubernetes contexts to use.
--controller-namespace string The namespace where the controller runs in. (default "kluctl-system")
--host string Host to bind to. Pass an empty string to bind to all addresses. Defaults to
'localhost' when run locally and to all hosts when run in-cluster.
--in-cluster This enables in-cluster functionality. This also enforces authentication.
--in-cluster-context string The context to use fo in-cluster functionality.
--kubeconfig existingfile Overrides the kubeconfig to use.
--only-api Only serve API without the actual UI.
--path-prefix string Specify the prefix of the path to serve the webui on. This is required when
using a reverse proxy, ingress or gateway that serves the webui on another
path than /. (default "/")
--port int Port to bind to. (default 8080)
Auth arguments:
Configure authentication.
--auth-admin-rbac-user string Specify the RBAC user to use for admin access. (default
"kluctl-webui-admin")
--auth-logout-return-param string Specify the parameter name to pass to the logout redirect url,
containing the return URL to redirect back.
--auth-logout-url string Specify the logout URL, to which the user should be redirected
after clearing the Kluctl Webui session.
--auth-oidc-admins-group stringArray Specify admins group names.'
--auth-oidc-client-id string Specify the ClientID.
--auth-oidc-client-secret-key string Specify the secret name for the ClientSecret. (default
"oidc-client-secret")
--auth-oidc-client-secret-name string Specify the secret name for the ClientSecret. (default "webui-secret")
--auth-oidc-display-name string Specify the name of the OIDC provider to be displayed on the login
page. (default "OpenID Connect")
--auth-oidc-group-claim string Specify claim for the groups.' (default "groups")
--auth-oidc-issuer-url string Specify the OIDC provider's issuer URL.
--auth-oidc-param stringArray Specify additional parameters to be passed to the authorize endpoint.
--auth-oidc-redirect-url string Specify the redirect URL.
--auth-oidc-scope stringArray Specify the scopes.
--auth-oidc-user-claim string Specify claim for the username.' (default "email")
--auth-oidc-viewers-group stringArray Specify viewers group names.'
--auth-secret-key string Specify the secret key for the secret used for internal encryption
of tokens and cookies. (default "auth-secret")
--auth-secret-name string Specify the secret name for the secret used for internal encryption
of tokens and cookies. (default "webui-secret")
--auth-static-admin-secret-key string Specify the secret key for the admin password. (default
"admin-password")
--auth-static-login-enabled Enable the admin user. (default true)
--auth-static-login-secret-name string Specify the secret name for the admin and viewer passwords.
(default "webui-secret")
--auth-static-viewer-secret-key string Specify the secret key for the viewer password. (default
"viewer-password")
--auth-viewer-rbac-user string Specify the RBAC user to use for viewer access. (default
"kluctl-webui-viewer")
1.7.9 - diff
Command
Usage: kluctl diff [flags]
Perform a diff between the locally rendered target and the already deployed target The output is by default in human readable form (a table combined with unified diffs). The output can also be changed to output a yaml file. Please note however that the format is currently not documented and prone to changes. After the diff is performed, the command will also search for prunable objects and list them.
Arguments
The following sets of arguments are available:
In addition, the following arguments are available:
Misc arguments:
Command specific arguments.
--discriminator string Override the target discriminator.
--force-apply Force conflict resolution when applying. See documentation for details
--force-replace-on-error Same as --replace-on-error, but also try to delete and re-create objects. See
documentation for more details.
--ignore-annotations Ignores changes in annotations when diffing
--ignore-kluctl-metadata Ignores changes in Kluctl related metadata (e.g. tags, discriminators, ...)
--ignore-labels Ignores changes in labels when diffing
--ignore-tags Ignores changes in tags when diffing
--no-obfuscate Disable obfuscation of sensitive/secret data
-o, --output-format stringArray Specify output format and target file, in the format 'format=path'. Format can
either be 'text' or 'yaml'. Can be specified multiple times. The actual format
for yaml is currently not documented and subject to change.
--render-output-dir string Specifies the target directory to render the project into. If omitted, a
temporary directory is used.
--replace-on-error When patching an object fails, try to replace it. See documentation for more
details.
--short-output When using the 'text' output format (which is the default), only names of
changes objects are shown instead of showing all changes.
--force-apply and --replace-on-error have the same meaning as in deploy.
1.7.10 - deploy
Command
Usage: kluctl deploy [flags]
Deploys a target to the corresponding cluster This command will also output a diff between the initial state and the state after deployment. The format of this diff is the same as for the ‘diff’ command. It will also output a list of prunable objects (without actually deleting them).
Arguments
The following sets of arguments are available:
- project arguments
- image arguments
- inclusion/exclusion arguments
- command results arguments
- helm arguments
- registry arguments
In addition, the following arguments are available:
Misc arguments:
Command specific arguments.
--abort-on-error Abort deploying when an error occurs instead of trying the remaining deployments
--discriminator string Override the target discriminator.
--dry-run Performs all kubernetes API calls in dry-run mode.
--force-apply Force conflict resolution when applying. See documentation for details
--force-replace-on-error Same as --replace-on-error, but also try to delete and re-create objects. See
documentation for more details.
--no-obfuscate Disable obfuscation of sensitive/secret data
--no-wait Don't wait for objects readiness.
-o, --output-format stringArray Specify output format and target file, in the format 'format=path'. Format
can either be 'text' or 'yaml'. Can be specified multiple times. The actual
format for yaml is currently not documented and subject to change.
--prune Prune orphaned objects directly after deploying. See the help for the 'prune'
sub-command for details.
--readiness-timeout duration Maximum time to wait for object readiness. The timeout is meant per-object.
Timeouts are in the duration format (1s, 1m, 1h, ...). If not specified, a
default timeout of 5m is used. (default 5m0s)
--render-output-dir string Specifies the target directory to render the project into. If omitted, a
temporary directory is used.
--replace-on-error When patching an object fails, try to replace it. See documentation for more
details.
--short-output When using the 'text' output format (which is the default), only names of
changes objects are shown instead of showing all changes.
-y, --yes Suppresses 'Are you sure?' questions and proceeds as if you would answer 'yes'.
–force-apply
kluctl implements deployments via server-side apply
and a custom automatic conflict resolution algorithm. This algurithm is an automatic implementation of the
“Don’t overwrite value, give up management claim”
method. It should work in most cases, but might still fail. In case of such failure, you can use --force-apply to
use the “Overwrite value, become sole manager” strategy instead.
Please note that this is a risky operation which might overwrite fields which were initially managed by kluctl but were then overtaken by other managers (e.g. by operators). Always use this option with caution and perform a dry-run before to ensure nothing unexpected gets overwritten.
–replace-on-error
In some situations, patching Kubernetes objects might fail for different reasons. In such cases, you can try
--replace-on-error to instruct kluctl to retry with an update operation.
Please note that this will cause all fields to be overwritten, even if owned by other field managers.
–force-replace-on-error
This flag will cause the same replacement attempt on failure as with --replace-on-error. In addition, it will fallback
to a delete+recreate operation in case the replace also fails.
Please note that this is a potentially risky operation, especially when an object carries some kind of important state.
–abort-on-error
kluctl does not abort a command when an individual object fails can not be updated. It collects all errors and warnings and outputs them instead. This option modifies the behaviour to immediately abort the command.
1.7.11 - prune
Command
Usage: kluctl prune [flags]
Searches the target cluster for prunable objects and deletes them
Arguments
The following sets of arguments are available:
- project arguments
- image arguments
- inclusion/exclusion arguments
- command results arguments
- helm arguments
- registry arguments
In addition, the following arguments are available:
Misc arguments:
Command specific arguments.
--discriminator string Override the target discriminator.
--dry-run Performs all kubernetes API calls in dry-run mode.
--no-obfuscate Disable obfuscation of sensitive/secret data
-o, --output-format stringArray Specify output format and target file, in the format 'format=path'. Format can
either be 'text' or 'yaml'. Can be specified multiple times. The actual format
for yaml is currently not documented and subject to change.
--render-output-dir string Specifies the target directory to render the project into. If omitted, a
temporary directory is used.
--short-output When using the 'text' output format (which is the default), only names of
changes objects are shown instead of showing all changes.
-y, --yes Suppresses 'Are you sure?' questions and proceeds as if you would answer 'yes'.
They have the same meaning as described in deploy.
1.7.12 - gitops logs
Command
Usage: kluctl gitops logs [flags]
Show logs from controller Print and watch logs of specified KluctlDeployments from the kluctl-controller.
Arguments
The following arguments are available:
GitOps arguments:
Specify gitops flags.
--context string Override the context to use.
--controller-namespace string The namespace where the controller runs in. (default "kluctl-system")
--kubeconfig existingfile Overrides the kubeconfig to use.
-l, --label-selector string If specified, KluctlDeployments are searched and filtered by this label
selector.
--local-source-override-port int Specifies the local port to which the source-override client should
connect to when running the controller locally.
--name string Specifies the name of the KluctlDeployment.
-n, --namespace string Specifies the namespace of the KluctlDeployment. If omitted, the current
namespace from your kubeconfig is used.
Misc arguments:
Command specific arguments.
--all Follow all controller logs, including all deployments and non-deployment related logs.
-f, --follow Follow logs after printing old logs.
--reconcile-id string If specified, logs are filtered for the given reconcile ID.
Command Results:
Configure how command results are stored.
--command-result-namespace string Override the namespace to be used when writing command results. (default
"kluctl-results")
Log arguments:
Configure logging.
--log-grouping-time duration Logs are by default grouped by time passed, meaning that they are printed in
batches to make reading them easier. This argument allows to modify the
grouping time. (default 1s)
--log-since duration Show logs since this time. (default 1m0s)
--log-time If enabled, adds timestamps to log lines
1.7.13 - gitops prune
Command
Usage: kluctl gitops prune [flags]
Trigger a GitOps prune This command will trigger an existing KluctlDeployment to perform a reconciliation loop with a forced prune. It does this by setting the annotation ‘kluctl.io/request-prune’ to the current time.
You can override many deployment relevant fields, see the list of command flags for details.
Arguments
The following arguments are available:
GitOps arguments:
Specify gitops flags.
--context string Override the context to use.
--controller-namespace string The namespace where the controller runs in. (default "kluctl-system")
--kubeconfig existingfile Overrides the kubeconfig to use.
-l, --label-selector string If specified, KluctlDeployments are searched and filtered by this label
selector.
--local-source-override-port int Specifies the local port to which the source-override client should
connect to when running the controller locally.
--name string Specifies the name of the KluctlDeployment.
-n, --namespace string Specifies the namespace of the KluctlDeployment. If omitted, the current
namespace from your kubeconfig is used.
Misc arguments:
Command specific arguments.
--abort-on-error Abort deploying when an error occurs instead of trying the remaining deployments
--dry-run Performs all kubernetes API calls in dry-run mode.
--force-apply Force conflict resolution when applying. See documentation for details
--force-replace-on-error Same as --replace-on-error, but also try to delete and re-create objects. See
documentation for more details.
--no-obfuscate Disable obfuscation of sensitive/secret data
-o, --output-format stringArray Specify output format and target file, in the format 'format=path'. Format can
either be 'text' or 'yaml'. Can be specified multiple times. The actual format
for yaml is currently not documented and subject to change.
--replace-on-error When patching an object fails, try to replace it. See documentation for more
details.
--short-output When using the 'text' output format (which is the default), only names of
changes objects are shown instead of showing all changes.
Command Results:
Configure how command results are stored.
--command-result-namespace string Override the namespace to be used when writing command results. (default
"kluctl-results")
Log arguments:
Configure logging.
--log-grouping-time duration Logs are by default grouped by time passed, meaning that they are printed in
batches to make reading them easier. This argument allows to modify the
grouping time. (default 1s)
--log-since duration Show logs since this time. (default 1m0s)
--log-time If enabled, adds timestamps to log lines
GitOps overrides:
Override settings for GitOps deployments.
--target-context string Overrides the context name specified in the target. If the selected target does
not specify a context or the no-name target is used, --context will override the
currently active context.
1.7.14 - gitops reconcile
Command
Usage: kluctl gitops reconcile [flags]
Trigger a GitOps reconciliation This command will trigger an existing KluctlDeployment to perform a reconciliation loop. It does this by setting the annotation ‘kluctl.io/request-reconcile’ to the current time.
You can override many deployment relevant fields, see the list of command flags for details.
Arguments
The following arguments are available:
GitOps arguments:
Specify gitops flags.
--context string Override the context to use.
--controller-namespace string The namespace where the controller runs in. (default "kluctl-system")
--kubeconfig existingfile Overrides the kubeconfig to use.
-l, --label-selector string If specified, KluctlDeployments are searched and filtered by this label
selector.
--local-source-override-port int Specifies the local port to which the source-override client should
connect to when running the controller locally.
--name string Specifies the name of the KluctlDeployment.
-n, --namespace string Specifies the namespace of the KluctlDeployment. If omitted, the current
namespace from your kubeconfig is used.
Misc arguments:
Command specific arguments.
--abort-on-error Abort deploying when an error occurs instead of trying the remaining deployments
--dry-run Performs all kubernetes API calls in dry-run mode.
--force-apply Force conflict resolution when applying. See documentation for details
--force-replace-on-error Same as --replace-on-error, but also try to delete and re-create objects. See
documentation for more details.
--replace-on-error When patching an object fails, try to replace it. See documentation for more details.
Command Results:
Configure how command results are stored.
--command-result-namespace string Override the namespace to be used when writing command results. (default
"kluctl-results")
Log arguments:
Configure logging.
--log-grouping-time duration Logs are by default grouped by time passed, meaning that they are printed in
batches to make reading them easier. This argument allows to modify the
grouping time. (default 1s)
--log-since duration Show logs since this time. (default 1m0s)
--log-time If enabled, adds timestamps to log lines
GitOps overrides:
Override settings for GitOps deployments.
--no-wait Don't wait for objects readiness.
--prune Prune orphaned objects directly after deploying. See the help for the 'prune'
sub-command for details.
--target-context string Overrides the context name specified in the target. If the selected target does
not specify a context or the no-name target is used, --context will override the
currently active context.
1.7.15 - gitops resume
Command
Usage: kluctl gitops resume [flags]
Resume a GitOps deployment This command will suspend a GitOps deployment by setting spec.suspend to ’true'.
Arguments
The following arguments are available:
GitOps arguments:
Specify gitops flags.
--context string Override the context to use.
--controller-namespace string The namespace where the controller runs in. (default "kluctl-system")
--kubeconfig existingfile Overrides the kubeconfig to use.
-l, --label-selector string If specified, KluctlDeployments are searched and filtered by this label
selector.
--local-source-override-port int Specifies the local port to which the source-override client should
connect to when running the controller locally.
--name string Specifies the name of the KluctlDeployment.
-n, --namespace string Specifies the namespace of the KluctlDeployment. If omitted, the current
namespace from your kubeconfig is used.
Misc arguments:
Command specific arguments.
--all If enabled, suspend all deployments.
--no-obfuscate Disable obfuscation of sensitive/secret data
-o, --output-format stringArray Specify output format and target file, in the format 'format=path'. Format can
either be 'text' or 'yaml'. Can be specified multiple times. The actual format
for yaml is currently not documented and subject to change.
--short-output When using the 'text' output format (which is the default), only names of
changes objects are shown instead of showing all changes.
Command Results:
Configure how command results are stored.
--command-result-namespace string Override the namespace to be used when writing command results. (default
"kluctl-results")
Log arguments:
Configure logging.
--log-grouping-time duration Logs are by default grouped by time passed, meaning that they are printed in
batches to make reading them easier. This argument allows to modify the
grouping time. (default 1s)
--log-since duration Show logs since this time. (default 1m0s)
--log-time If enabled, adds timestamps to log lines
1.7.16 - gitops suspend
Command
Usage: kluctl gitops suspend [flags]
Suspend a GitOps deployment This command will suspend a GitOps deployment by setting spec.suspend to ’true'.
Arguments
The following arguments are available:
GitOps arguments:
Specify gitops flags.
--context string Override the context to use.
--controller-namespace string The namespace where the controller runs in. (default "kluctl-system")
--kubeconfig existingfile Overrides the kubeconfig to use.
-l, --label-selector string If specified, KluctlDeployments are searched and filtered by this label
selector.
--local-source-override-port int Specifies the local port to which the source-override client should
connect to when running the controller locally.
--name string Specifies the name of the KluctlDeployment.
-n, --namespace string Specifies the namespace of the KluctlDeployment. If omitted, the current
namespace from your kubeconfig is used.
Misc arguments:
Command specific arguments.
--all If enabled, suspend all deployments.
--no-obfuscate Disable obfuscation of sensitive/secret data
-o, --output-format stringArray Specify output format and target file, in the format 'format=path'. Format can
either be 'text' or 'yaml'. Can be specified multiple times. The actual format
for yaml is currently not documented and subject to change.
--short-output When using the 'text' output format (which is the default), only names of
changes objects are shown instead of showing all changes.
Command Results:
Configure how command results are stored.
--command-result-namespace string Override the namespace to be used when writing command results. (default
"kluctl-results")
Log arguments:
Configure logging.
--log-grouping-time duration Logs are by default grouped by time passed, meaning that they are printed in
batches to make reading them easier. This argument allows to modify the
grouping time. (default 1s)
--log-since duration Show logs since this time. (default 1m0s)
--log-time If enabled, adds timestamps to log lines
1.7.17 - gitops validate
Command
Usage: kluctl gitops validate [flags]
Trigger a GitOps validate This command will trigger an existing KluctlDeployment to perform a reconciliation loop with a forced validation. It does this by setting the annotation ‘kluctl.io/request-validate’ to the current time.
You can override many deployment relevant fields, see the list of command flags for details.
Arguments
The following arguments are available:
GitOps arguments:
Specify gitops flags.
--context string Override the context to use.
--controller-namespace string The namespace where the controller runs in. (default "kluctl-system")
--kubeconfig existingfile Overrides the kubeconfig to use.
-l, --label-selector string If specified, KluctlDeployments are searched and filtered by this label
selector.
--local-source-override-port int Specifies the local port to which the source-override client should
connect to when running the controller locally.
--name string Specifies the name of the KluctlDeployment.
-n, --namespace string Specifies the namespace of the KluctlDeployment. If omitted, the current
namespace from your kubeconfig is used.
Misc arguments:
Command specific arguments.
--abort-on-error Abort deploying when an error occurs instead of trying the remaining deployments
--dry-run Performs all kubernetes API calls in dry-run mode.
--force-apply Force conflict resolution when applying. See documentation for details
--force-replace-on-error Same as --replace-on-error, but also try to delete and re-create objects. See
documentation for more details.
-o, --output stringArray Specify output target file. Can be specified multiple times
--replace-on-error When patching an object fails, try to replace it. See documentation for more details.
--warnings-as-errors Consider warnings as failures
Command Results:
Configure how command results are stored.
--command-result-namespace string Override the namespace to be used when writing command results. (default
"kluctl-results")
Log arguments:
Configure logging.
--log-grouping-time duration Logs are by default grouped by time passed, meaning that they are printed in
batches to make reading them easier. This argument allows to modify the
grouping time. (default 1s)
--log-since duration Show logs since this time. (default 1m0s)
--log-time If enabled, adds timestamps to log lines
GitOps overrides:
Override settings for GitOps deployments.
--target-context string Overrides the context name specified in the target. If the selected target does
not specify a context or the no-name target is used, --context will override the
currently active context.
1.7.18 - oci push
Command
Usage: kluctl oci push [flags]
Push to an oci repository The push command creates a tarball from the current project and uploads the artifact to an OCI repository.
Arguments
The following sets of arguments are available:
In addition, the following arguments are available:
Misc arguments:
Command specific arguments.
--annotation stringArray Set custom OCI annotations in the format '<key>=<value>'
--output string the format in which the artifact digest should be printed, can be 'json' or 'yaml'
--timeout duration Specify timeout for all operations, including loading of the project, all
external api calls and waiting for readiness. (default 10m0s)
--url string Specifies the artifact URL. This argument is required.
1.7.19 - delete
Command
Usage: kluctl delete [flags]
Delete a target (or parts of it) from the corresponding cluster Objects are located based on the target discriminator.
WARNING: This command will also delete objects which are not part of your deployment project (anymore). It really only decides based on the discriminator and does NOT take the local target/state into account!
Arguments
The following sets of arguments are available:
- project arguments
- image arguments
- inclusion/exclusion arguments
- command results arguments
- helm arguments
- registry arguments
In addition, the following arguments are available:
Misc arguments:
Command specific arguments.
--discriminator string Override the discriminator used to find objects for deletion.
--dry-run Performs all kubernetes API calls in dry-run mode.
--no-obfuscate Disable obfuscation of sensitive/secret data
--no-wait Don't wait for deletion of objects to finish.'
-o, --output-format stringArray Specify output format and target file, in the format 'format=path'. Format can
either be 'text' or 'yaml'. Can be specified multiple times. The actual format
for yaml is currently not documented and subject to change.
--render-output-dir string Specifies the target directory to render the project into. If omitted, a
temporary directory is used.
--short-output When using the 'text' output format (which is the default), only names of
changes objects are shown instead of showing all changes.
-y, --yes Suppresses 'Are you sure?' questions and proceeds as if you would answer 'yes'.
They have the same meaning as described in deploy.
1.7.20 - helm-pull
Command
Usage: kluctl helm-pull [flags]
Recursively searches for ‘helm-chart.yaml’ files and pre-pulls the specified Helm charts Kluctl requires Helm Charts to be pre-pulled by default, which is handled by this command. It will collect all required Charts and versions and pre-pull them into .helm-charts. To disable pre-pulling for individual charts, set ‘skipPrePull: true’ in helm-chart.yaml.
See helm-integration for more details.
Arguments
The following sets of arguments are available:
1.7.21 - helm-update
Command
Usage: kluctl helm-update [flags]
Recursively searches for ‘helm-chart.yaml’ files and checks for new available versions Optionally performs the actual upgrade and/or add a commit to version control.
Arguments
The following sets of arguments are available:
In addition, the following arguments are available:
Misc arguments:
Command specific arguments.
--commit Create a git commit for every updated chart
-i, --interactive Ask for every Helm Chart if it should be upgraded.
--upgrade Write new versions into helm-chart.yaml and perform helm-pull afterwards
1.7.22 - list-images
Command
Usage: kluctl list-images [flags]
Renders the target and outputs all images used via ‘images.get_image(…) The result is a compatible with yaml files expected by –fixed-images-file.
If fixed images (’-f/–fixed-image’) are provided, these are also taken into account, as described in the deploy command.
Arguments
The following sets of arguments are available:
In addition, the following arguments are available:
Misc arguments:
Command specific arguments.
--kubernetes-version string Specify the Kubernetes version that will be assumed. This will also override
the kubeVersion used when rendering Helm Charts.
--offline-kubernetes Run command in offline mode, meaning that it will not try to connect the
target cluster
-o, --output stringArray Specify output target file. Can be specified multiple times
--render-output-dir string Specifies the target directory to render the project into. If omitted, a
temporary directory is used.
--simple Output a simplified version of the images list
1.7.23 - poke-images
Command
Usage: kluctl poke-images [flags]
Replace all images in target This command will fully render the target and then only replace images instead of fully deploying the target. Only images used in combination with ‘images.get_image(…)’ are replaced
Arguments
The following sets of arguments are available:
- project arguments
- image arguments
- inclusion/exclusion arguments
- command results arguments
- helm arguments
- registry arguments
In addition, the following arguments are available:
Misc arguments:
Command specific arguments.
--dry-run Performs all kubernetes API calls in dry-run mode.
--no-obfuscate Disable obfuscation of sensitive/secret data
-o, --output-format stringArray Specify output format and target file, in the format 'format=path'. Format can
either be 'text' or 'yaml'. Can be specified multiple times. The actual format
for yaml is currently not documented and subject to change.
--render-output-dir string Specifies the target directory to render the project into. If omitted, a
temporary directory is used.
--short-output When using the 'text' output format (which is the default), only names of
changes objects are shown instead of showing all changes.
-y, --yes Suppresses 'Are you sure?' questions and proceeds as if you would answer 'yes'.
1.7.24 - render
Command
Usage: kluctl render [flags]
Renders all resources and configuration files Renders all resources and configuration files and stores the result in either a temporary directory or a specified directory.
Arguments
The following sets of arguments are available:
In addition, the following arguments are available:
Misc arguments:
Command specific arguments.
--kubernetes-version string Specify the Kubernetes version that will be assumed. This will also override
the kubeVersion used when rendering Helm Charts.
--offline-kubernetes Run command in offline mode, meaning that it will not try to connect the
target cluster
--print-all Write all rendered manifests to stdout
--render-output-dir string Specifies the target directory to render the project into. If omitted, a
temporary directory is used.
1.7.25 - validate
Command
Usage: kluctl validate [flags]
Validates the already deployed deployment This means that all objects are retrieved from the cluster and checked for readiness.
TODO: This needs to be better documented!
Arguments
The following sets of arguments are available:
In addition, the following arguments are available:
Misc arguments:
Command specific arguments.
-o, --output stringArray Specify output target file. Can be specified multiple times
--render-output-dir string Specifies the target directory to render the project into. If omitted, a
temporary directory is used.
--sleep duration Sleep duration between validation attempts (default 5s)
--wait duration Wait for the given amount of time until the deployment validates
--warnings-as-errors Consider warnings as failures
1.7.26 - webui build
Command
Usage: kluctl webui build [flags]
Build the static Kluctl Webui This command will build the static Kluctl Webui.
Arguments
The following arguments are available:
Misc arguments:
Command specific arguments.
--all-contexts Use all Kubernetes contexts found in the kubeconfig.
--context stringArray List of kubernetes contexts to use. Defaults to the current context.
--max-results int Specify the maximum number of results per target. (default 1)
--path string Output path.
2 - Kluctl GitOps
GitOps in Kluctl is implemented through the Kluctl Controller, which must be installed to your target cluster.
The Kluctl Controller is a Kubernetes operator which implements the KluctlDeployment
custom resource. This resource allows to define a Kluctl deployment that should be constantly reconciled (re-deployed)
whenever the deployment changes.
It is suggested to read through the GitOps Recipe to get a basic understanding of how to use it.
Motivation and Philosophy
Kluctl tries its best to implement all its features via Kluctl projects, meaning that the deployments are, at least theoretically, deployable from the CLI at all times. The Kluctl Controller does not add functionality on top of that and thus does not couple your deployments to a running controller.
Instead, the KluctlDeployment custom resource acts as an interface to the deployment. It tries to offer the same
functionality and options as offered by the CLI, but through a custom resource instead of a CLI invocation.
As an example, arguments passed via -a arg=value can be passed to the custom resource via the spec.args field.
The same applies to options like --dry-run, which equals to spec.dryRun: true in the custom resource. Check the
documentation of KluctlDeployment for more such options.
GitOps Commands
Kluctl GitOps deployments can be controlled via the Kluctl CLI interface, e.g. with
kluctl gitops deploy --namespace my-ns --name my-deployment, which will trigger a deployment and wait for it to finish.
See commands and the GitOps recipe for more details.
Kluctl Webui
The same deployments can also be controlled and monitored via the Kluctl Webui.
Installation
Installation instructions can be found here
Design
The reconciliation process consists of multiple steps which are constantly repeated:
- clone the root Kluctl project via Git
- prepare the Kluctl deployment by rendering the whole deployment
- deploy the specified target via kluctl deploy if the rendered resources changed
- prune orphaned objects via kluctl prune
- validate the deployment status via kluctl validate
- drift-detection is performed to allow the Kluctl Webui to show drift.
Reconciliation is performed on a configurable interval. A single reconciliation iteration will first clone and prepare the project. Only when the rendered resources indicate a change (by using a hash internally), the controller will initiate a deployment. After the deployment, the controller will also perform pruning (only if prune: true is set).
When the KluctlDeployment is removed from the cluster, the controller cal also delete all resources belonging to
that deployment. This will only happen if delete: true is set.
Deletion and pruning is based on the discriminator of the given target.
A KluctlDeployment can be suspended. While suspended, the controller
will skip reconciliation, including deletion and pruning.
The API design of the controller can be found at kluctldeployment.gitops.kluctl.io/v1beta1.
Example
After installing the Kluctl Controller, we can create a KluctlDeployment that automatically deploys the
Microservices Demo.
Create a KluctlDeployment that uses the demo project source to deploy the test target to the same cluster that the
controller runs on.
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: microservices-demo-test
namespace: kluctl-system
spec:
interval: 10m
source:
git:
url: https://github.com/kluctl/kluctl-examples.git
path: "./microservices-demo/3-templating-and-multi-env/"
timeout: 2m
target: test
context: default
prune: true
This example will deploy a fully-fledged microservices application with multiple backend services, frontends and
databases, all via one single KluctlDeployment.
To deploy the same Kluctl project to another target (e.g. prod), simply create the following resource.
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: microservices-demo-prod
namespace: kluctl-system
spec:
interval: 10m
source:
git:
url: https://github.com/kluctl/kluctl-examples.git
path: "./microservices-demo/3-templating-and-multi-env/"
timeout: 2m
target: prod
context: default
prune: true
2.1 - Installation
The controller can be installed via two available options.
Using the “install” sub-command
The kluctl controller install command can be used to install the
controller. It will use an embedded version of the Controller Kluctl deployment project
found here.
Using a Kluctl deployment
To manage and install the controller via Kluctl, you can use a Git include in your own deployment:
deployments:
- git:
url: https://github.com/kluctl/kluctl.git
subDir: install/controller
ref:
tag: v2.28.1
2.2 - Specs
2.2.1 - v1beta1 specs
gitops.kluctl.io/v1beta1
This is the v1beta1 API specification for defining continuous delivery pipelines of Kluctl Deployments.
Specification
2.2.1.1 - KluctlDeployment
The KluctlDeployment API defines a deployment of a target
from a Kluctl Project.
Example
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: microservices-demo-prod
spec:
interval: 5m
source:
git:
url: https://github.com/kluctl/kluctl-examples.git
path: "./microservices-demo/3-templating-and-multi-env/"
timeout: 2m
target: prod
context: default
prune: true
delete: true
manual: true
In the above example a KluctlDeployment is being created that defines the deployment based on the Kluctl project.
The deployment is performed every 5 minutes. It will deploy the prod
target and then prune orphaned objects afterward.
When the KluctlDeployment gets deleted, delete: true will cause the controller to actually delete the target
resources.
It uses the default context provided by the default service account and thus overrides the context specified in the
target definition.
Spec fields
source
The KluctlDeployment spec.source specifies the source repository to be used. Example:
Multiple source types are supported, as described in the following subsections.
Git source
Specifies a Git repository to load the project source from.
Example:
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: example
spec:
source:
git:
url: https://github.com/kluctl/kluctl-examples.git
path: path/to/project
ref:
branch: my-branch
credentials:
git:
- host: github.com
path: kluctl/*
secretRef:
name: git-credentials
...
The url specifies the git clone url. It can either be a https or a git/ssh url. Git/Ssh url will require a secret
to be provided with credentials.
The path specifies the subdirectory where the Kluctl project is located.
The ref provides the Git reference to be used. The ref field has the same format as in
git includes.
See Git authentication for details on authentication via the spec.credentials.git field.
OCI source
Specifies a OCI artifact to load the project source from. The artifact must have been pushed via the kluctl oci push command.
Example:
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: example
spec:
source:
oci:
url: oci://ghcr.io/kluctl/kluctl-examples/simple
path: my-subdir
ref:
tag: latest
credentials:
oci:
- registry: ghcr.io
repository: kluctl/**
secretRef:
name: oci-credentials
...
The url specifies the OCI repository url. It must use the oci:// scheme. It is not allowed to add tags or digests to
the url. Instead, use the dedicated ref field.
The path specifies the subdirectory where the Kluctl project is located.
The ref provides the Git reference to be used. The ref field has the same format as in
oci includes.
See OCI authentication for details on authentication via the spec.credentials.oci field.
interval
See Reconciliation.
deployInterval
If set, the controller will periodically force a deployment, even if the rendered manifests have not changed. See Reconciliation for more details.
timeout
The maximum time granted for the all the work needed to perform in a reconciliation. If timeout is not specified,
then the value of deployInterval is used as the default value, but only if it is set. If deployInterval is not set,
then the value of interval is used as default.
When a reconciliation takes longer then the determined timeout value, then the reconciliation is aborted with an error.
suspend
See Reconciliation.
target
spec.target specifies the target to be deployed. It must exist in the Kluctl projects
kluctl.yaml targets list.
This field is optional and can be omitted if the referenced Kluctl project allows deployments without targets.
targetNameOverride
spec.targetNameOverride will set or override the name of the target. This is equivalent to passing
--target-name-override to kluctl deploy.
context
spec.context will override the context used while deploying. This is equivalent to passing --context to
kluctl deploy.
deployMode
By default, the operator will perform a full deployment, which is equivalent to using the kluctl deploy command.
As an alternative, the controller can be instructed to only perform a kluctl poke-images command. Please
see poke-images for details on the command. To do so, set spec.deployMode
field to poke-images.
Example:
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: microservices-demo-prod
spec:
interval: 5m
source:
git:
url: https://github.com/kluctl/kluctl-examples.git
path: "./microservices-demo/3-templating-and-multi-env/"
timeout: 2m
target: prod
context: default
deployMode: poke-images
prune
To enable pruning, set spec.prune to true. This will cause the controller to run kluctl prune after each
successful deployment.
delete
To enable deletion, set spec.delete to true. This will cause the controller to run kluctl delete when the
KluctlDeployment gets deleted.
manual
spec.manual enables manually approved/triggered deployments. This means, that deployments are performed in dry-run
mode until the most recent deployment is approved.
This feature is most useful in combination with the Kluctl Webui, which offers a visualisation and proper actions for this feature.
Internally, approval happens by setting spec.manualObjectsHash to the objects hash of the approved command result.
args
spec.args is an object representing arguments
passed to the deployment. Example:
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: example
spec:
interval: 5m
source:
git:
url: https://github.com/kluctl/kluctl-examples.git
path: "./microservices-demo/3-templating-and-multi-env/"
timeout: 2m
target: prod
context: default
args:
arg1: value1
arg2: value2
arg3:
k1: v1
k2: v2
The above example is equivalent to calling kluctl deploy -t prod -a arg1=value1 -a arg2=value2.
images
spec.images specifies a list of fixed images to be used by
image.get_image(...). Example:
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: example
spec:
interval: 5m
source:
git:
url: https://example.com
timeout: 2m
target: prod
images:
- image: nginx
resultImage: nginx:1.21.6
namespace: example-namespace
deployment: Deployment/example
- image: registry.gitlab.com/my-org/my-repo/image
resultImage: registry.gitlab.com/my-org/my-repo/image:1.2.3
The above example will cause the images.get_image("nginx") invocations of the example Deployment to return
nginx:1.21.6. It will also cause all images.get_image("registry.gitlab.com/my-org/my-repo/image") invocations
to return registry.gitlab.com/my-org/my-repo/image:1.2.3.
The fixed images provided here take precedence over the ones provided in the target definition.
spec.images is equivalent to calling kluctl deploy -t prod --fixed-image=nginx:example-namespace:Deployment/example=nginx:1.21.6 ...
and to kluctl deploy -t prod --fixed-images-file=fixed-images.yaml with fixed-images.yaml containing:
images:
- image: nginx
resultImage: nginx:1.21.6
namespace: example-namespace
deployment: Deployment/example
- image: registry.gitlab.com/my-org/my-repo/image
resultImage: registry.gitlab.com/my-org/my-repo/image:1.2.3
dryRun
spec.dryRun is a boolean value that turns the deployment into a dry-run deployment. This is equivalent to calling
kluctl deploy -t prod --dry-run.
noWait
spec.noWait is a boolean value that disables all internal waiting (hooks and readiness). This is equivalent to calling
kluctl deploy -t prod --no-wait.
forceApply
spec.forceApply is a boolean value that causes kluctl to solve conflicts via force apply. This is equivalent to calling
kluctl deploy -t prod --force-apply.
replaceOnError and forceReplaceOnError
spec.replaceOnError and spec.forceReplaceOnError are both boolean values that cause kluctl to perform a replace
after a failed apply. forceReplaceOnError goes a step further and deletes and recreates the object in question.
These are equivalent to calling kluctl deploy -t prod --replace-on-error and kluctl deploy -t prod --force-replace-on-error.
abortOnError
spec.abortOnError is a boolean value that causes kluctl to abort as fast as possible in case of errors. This is equivalent to calling
kluctl deploy -t prod --abort-on-error.
includeTags, excludeTags, includeDeploymentDirs and excludeDeploymentDirs
spec.includeTags and spec.excludeTags are lists of tags to be used in inclusion/exclusion logic while deploying.
These are equivalent to calling kluctl deploy -t prod --include-tag <tag1> and kluctl deploy -t prod --exclude-tag <tag2>.
spec.includeDeploymentDirs and spec.excludeDeploymentDirs are lists of relative deployment directories to be used in
inclusion/exclusion logic while deploying. These are equivalent to calling kluctl deploy -t prod --include-tag <tag1>
and kluctl deploy -t prod --exclude-tag <tag2>.
Reconciliation
The KluctlDeployment spec.interval tells the controller at which interval to try reconciliations.
The interval time units are s, m and h e.g. interval: 5m, the minimum value should be over 60 seconds.
At each reconciliation run, the controller will check if any rendered objects have been changes since the last deployment and then perform a new deployment if changes are detected. Changes are tracked via a hash consisting of all rendered objects.
To enforce periodic full deployments even if nothing has changed, spec.deployInterval can be used to specify an
interval at which forced deployments must be performed by the controller.
The KluctlDeployment reconciliation can be suspended by setting spec.suspend to true. Suspension will however not
prevent manual reconciliation requests via the kluctl gitops sub-commands.
Manual requests/reconciliation
The controller can be told to reconcile the KluctlDeployment outside of the specified interval
by using the kluctl gitops sub-commands.
On-demand reconciliation example:
$ kluctl gitops deploy --namespace my-namespace --name my-deployment
You can also perform manual requests while temporarily overriding deployment configurations, e.g.:
$ kluctl gitops deploy --namespace my-namespace --name my-deployment --force-apply
Local source overrides are also possible, allowing you to test changes before pushing them:
$ kluctl gitops diff --namespace my-namespace --name my-deployment --local-git-override=github.com/exaple-org/example-project=/local/path/to/modified/repo
When --namespace and --name are omitted, the CLI will try to auto-detect the deployment on the current cluster
and suggest the auto-detected deployment to you.
Kubeconfigs and RBAC
As Kluctl is meant to be a CLI-first tool, it expects a kubeconfig to be present while deployments are performed. The controller will generate such kubeconfigs on-the-fly before performing the actual deployment.
The kubeconfig can be generated from 3 different sources:
- The default impersonation service account specified at controller startup (via
--default-service-account) - The service account specified via
spec.serviceAccountNamein the KluctlDeployment - The secret specified via
spec.kubeConfigin the KluctlDeployment.
The behavior/functionality of 1. and 2. is comparable to how the kustomize-controller handles impersonation, with the difference that a kubeconfig with a “default” context is created in-between.
spec.kubeConfig will simply load the kubeconfig from data.value of the specified secret.
Kluctl targets specify a context name that is expected to
be present in the kubeconfig while deploying. As the context found in the generated kubeconfig does not necessarily
have the correct name, spec.context can be used to while deploying. This is especially useful
when using service account based kubeconfigs, as these always have the same context with the name “default”.
Here is an example of a deployment that uses the service account “prod-service-account” and overrides the context appropriately (assuming the Kluctl cluster config for the given target expects a “prod” context):
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: example
namespace: kluctl-system
spec:
interval: 10m
source:
git:
url: https://github.com/kluctl/kluctl-examples.git
path: "./microservices-demo/3-templating-and-multi-env/"
target: prod
serviceAccountName: prod-service-account
context: default
Credentials
A KluctlDeployment can specify multiple sets of credentials for different kind of repositories and registries. These
are specified through the spec.credentials field, which specifies multiple list of credentials.
Git authentication
Git authentication can be specified via spec.credentials.git, which is a list of credential configs. Each entry
specifies information to match Git repositories and a reference to a Kubernetes secret.
Each time the controller needs to access a git repository, it will iterate through this list and pick the first one matching.
Example:
...
spec:
source:
git:
url: https://github.com/my-org/my-repo.git
credentials:
git:
- host: github.com
path: my-org/*
secretRef:
name: my-git-secrets
...
Each entry has the following fields:
host is required and specifies the hostname to apply this set of credentials. It can also be set to *, meaning that
it will match all git hosts. * will however be ignored for https based urls to avoid leaking credentials.
path is optional and allows to filter for different paths on the same host. This is for example useful
when public Git providers are used, for example github.com. For these, you can for example use my-org/* as pattern to
tell the controller that it should use this set of credentials only for projects below the my-org GitHub organisation.
secretRef is required and specifies the name of the secret that contains the actual credentials.
The following authentication types are supported through the referenced secret.
Basic access authentication
To authenticate towards a Git repository over HTTPS using basic access
authentication (in other words: using a username and password), the referenced
Secret is expected to contain .data.username and .data.password values.
---
apiVersion: v1
kind: Secret
metadata:
name: basic-access-auth
type: Opaque
data:
username: <BASE64>
password: <BASE64>
HTTPS Certificate Authority
To provide a Certificate Authority to trust while connecting with a Git
repository over HTTPS, the referenced Secret can contain a .data.caFile
value.
---
apiVersion: v1
kind: Secret
metadata:
name: https-ca-credentials
namespace: default
type: Opaque
data:
caFile: <BASE64>
SSH authentication
To authenticate towards a Git repository over SSH, the referenced Secret is
expected to contain identity and known_hosts fields. With the respective
private key of the SSH key pair, and the host keys of the Git repository.
---
apiVersion: v1
kind: Secret
metadata:
name: ssh-credentials
type: Opaque
stringData:
identity: |
-----BEGIN OPENSSH PRIVATE KEY-----
...
-----END OPENSSH PRIVATE KEY-----
known_hosts: |
github.com ecdsa-sha2-nistp256 AAAA...
Helm Repository authentication
Kluctl allows to integrate Helm Charts in two different ways. One is to pre-pull charts and put them into version control, making it unnecessary to pull them at deploy time. This option also means that you don’t have to take any special care on the controller side.
The other way is to let Kluctl pull Helm Charts at deploy time. In that case, you have to ensure that the controller has the necessary access to the Helm repositories.
Helm Repository authentication can be specified via spec.credentials.helm, which is a list of credential configs. Each entry
specifies information to match Helm repositories and a reference to a Kubernetes secret.
Each time the controller needs to access a Helm repository, it will iterate through this list and pick the first one matching.
Example:
...
spec:
source:
git:
url: https://github.com/my-org/my-repo.git
credentials:
helm:
- host: my-repo.com
path: some-path/*
secretRef:
name: my-helm-secrets
...
Each entry has the following fields:
host is required and specifies the hostname to apply this set of credentials.
path is optional and allows to filter for different paths on the same host. The behavior is identical to how
Git credentials handle it.
secretRef is required and specifies the name of the secret that contains the actual credentials.
The following authentication types are supported through the referenced secret.
Basic access authentication
To authenticate towards a Helm repository over HTTP/HTTPS using basic access
authentication (in other words: using a username and password), the referenced
Secret is expected to contain .data.username and .data.password values.
apiVersion: v1
kind: Secret
metadata:
name: my-helm-creds
namespace: kluctl-system
stringData:
username: my-user
password: my-password
TLS authentication
For TLS authentication, see the following example secret:
apiVersion: v1
kind: Secret
metadata:
name: my-helm-creds
namespace: kluctl-system
data:
certFile: <BASE64>
keyFile: <BASE64>
# NOTE: The following values can be supplied without the above values and for all other (e.g. basic) authentication types as well
caFile: <BASE64>
insecureSkipTlsVerify: "true" # this field is optional
passCredentialsAll: "true" # this field is optional
certFile and keyFile optionally specify a client certificate and key pair to use for client certificate based
authentication. caFile specifies a CA bundle to use when TSL/https verification is performed.
If insecureSkipTlsVerify is set to true, TLS verification is skipped.
If passCredentialsAll is set to true, Kluctl will pass credentials to all domains. See https://helm.sh/docs/helm/helm_repo_add/ for details.
OCI registry authentication
OCI registry authentication can be specified via spec.credentials.oci, which is a list of credential configs. Each entry
specifies information to match OCI registries and a reference to a Kubernetes secret.
Each time the controller needs to access an OCI registry, it will iterate through this list and pick the first one matching. This also includes OCI registry usages via the Helm integration.
Example:
...
spec:
source:
git:
url: https://github.com/my-org/my-repo.git
credentials:
oci:
- registry: docker.com
repository: my-org/*
secretRef:
name: my-oci-secrets
...
Each entry has the following fields:
registry is required and specifies the registry name to apply this set of credentials.
repository is optional and allows to filter for different repositories in the same registry. Wildcards can also be used.
If omitted, all repositories on the specified registry will match.
secretRef is required and specifies the name of the secret that contains the actual credentials.
The following authentication types are supported through the referenced secret.
Basic access authentication
To authenticate towards an OCI registry over HTTP/HTTPS using basic access
authentication (in other words: using a username and password), the referenced
Secret is expected to contain .data.username and .data.password values.
apiVersion: v1
kind: Secret
metadata:
name: my-oci-secrets
namespace: kluctl-system
stringData:
username: my-user
password: my-password
Token based authentication
To authenticate via a bearer token, use specify .data.token in the referenced secret.
apiVersion: v1
kind: Secret
metadata:
name: my-oci-secrets
namespace: kluctl-system
stringData:
token: my-token
TLS authentication
For TLS authentication, see the following example secret:
apiVersion: v1
kind: Secret
metadata:
name: my-oci-creds
namespace: kluctl-system
data:
certFile: <BASE64>
keyFile: <BASE64>
# NOTE: The following values can be supplied without the above values and for all other (e.g. basic) authentication types as well
caFile: <BASE64>
insecureSkipTlsVerify: "true" # this field is optional
plainHttp: "true" # this field is optional
certFile and keyFile optionally specify a client certificate and key pair to use for client certificate based
authentication. caFile specifies a CA bundle to use when TSL/https verification is performed.
If insecureSkipTlsVerify is set to true, TLS verification is skipped.
If plainHttp if set to true, HTTPS is disabled and HTTP is used instead.
Deprecated ways of credentials configurations
Kluctl still supports the deprecated spec.source.credentials, spec.source.secretRef and spec.helmCredentials fields
in the v1beta1 api version. These fields are however deprecated and will be removed in the next version bump.
Secrets Decryption
Kluctl offers a SOPS Integration that allows to use encrypted
manifests and variable sources in Kluctl deployments. Decryption by the controller is also supported and currently
mirrors how the Secrets Decryption configuration
of the Flux Kustomize Controller. To configure it in the KluctlDeployment, simply set the decryption field in the
spec:
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: example
namespace: kluctl-system
spec:
decryption:
provider: sops
secretRef:
name: sops-keys
...
The sops-keys Secret has the same format as in the
Flux Kustomize Controller.
AWS KMS with IRSA
In addition to the AWS KMS Secret Entry
in the secret and the global AWS KMS
authentication via the controller’s service account, the Kluctl controller also supports using the IRSA role of the
impersonated service account of the KluctlDeployment (specified via serviceAccountName in the spec or
--default-service-account):
apiVersion: v1
kind: ServiceAccount
metadata:
name: kluctl-deployment
namespace: kluctl-system
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::123456:role/my-irsa-enabled-role
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: kluctl-deployment
namespace: kluctl-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
# watch out, don't use cluster-admin if you don't trust the deployment
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kluctl-deployment
namespace: kluctl-system
---
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: example
namespace: kluctl-system
spec:
serviceAccountName: kluctl-deployment
decryption:
provider: sops
# you can also leave out the secretRef if you don't provide addinional keys
secretRef:
name: sops-keys
...
Status
When the controller completes a deployments, it reports the result in the status sub-resource.
A successful reconciliation sets the ready condition to true.
...
status:
conditions:
- lastTransitionTime: "2022-07-07T11:48:14Z"
message: "deploy: ok"
reason: ReconciliationSucceeded
status: "True"
type: Ready
lastDeployResult:
...
lastPruneResult:
...
lastValidateResult:
...
You can wait for the controller to complete a reconciliation with:
$ kubectl wait kluctldeployment/backend --for=condition=ready
A failed reconciliation sets the ready condition to false:
...
status:
conditions:
- lastTransitionTime: "2022-05-04T10:18:11Z"
message: target invalid-name not found in kluctl project
reason: PrepareFailed
status: "False"
type: Ready
lastDeployResult:
...
lastPruneResult:
...
lastValidateResult:
...
Note that the lastDeployResult, lastPruneResult and lastValidateResult are only updated on a successful reconciliation.
2.3 - Metrics
2.3.1 - v1beta1 metrics
Prometheus Metrics
The controller exports several metrics in the OpenMetrics compatible format. They can be scraped by all sorts of monitoring solutions (e.g. Prometheus) or stored in a database. Because the controller is based on controller-runtime, all the default metrics as well as the following controller-specific custom metrics are exported:
2.3.1.1 - Metrics of the KluctlDeployment Controller
Exported Metrics References
| Metrics name | Type | Description |
|---|---|---|
| deployment_duration_seconds | Histogram | How long a single deployment takes in seconds. |
| number_of_changed_objects | Gauge | How many objects have been changed by a single deployment. |
| number_of_deleted_objects | Gauge | How many objects have been deleted by a single deployment. |
| number_of_errors | Gauge | How many errors are related to a single deployment. |
| number_of_images | Gauge | Number of images of a single deployment. |
| number_of_orphan_objects | Gauge | How many orphans are related to a single deployment. |
| number_of_warnings | Gauge | How many warnings are related to a single deployment. |
| prune_duration_seconds | Histogram | How long a single prune takes in seconds. |
| validate_duration_seconds | Histogram | How long a single validate takes in seconds. |
| deployment_interval_seconds | Gauge | The configured deployment interval of a single deployment. |
| dry_run_enabled | Gauge | Is dry-run enabled for a single deployment. |
| last_object_status | Gauge | Last object status of a single deployment. Zero means failure and one means success. |
| last_deploy_start_timestamp_seconds | Gauge | Start time of the last deployment. |
| prune_enabled | Gauge | Is pruning enabled for a single deployment. |
| delete_enabled | Gauge | Is deletion enabled for a single deployment. |
| source_spec | Gauge | The configured source spec of a single deployment exported via labels. |
2.4 - Kluctl Controller API reference
Packages:
gitops.kluctl.io/v1beta1
Package v1beta1 contains API Schema definitions for the gitops.kluctl.io v1beta1 API group.
Resource Types:Decryption
(Appears on: KluctlDeploymentSpec)
Decryption defines how decryption is handled for Kubernetes manifests.
| Field | Description |
|---|---|
providerstring | Provider is the name of the decryption engine. |
secretRefLocalObjectReference | (Optional) The secret name containing the private OpenPGP keys used for decryption. |
serviceAccountstring | (Optional) ServiceAccount specifies the service account used to authenticate against cloud providers. This is currently only usable for AWS KMS keys. The specified service account will be used to authenticate to AWS by signing a token in an IRSA compliant way. |
HelmCredentials
(Appears on: KluctlDeploymentSpec)
| Field | Description |
|---|---|
secretRefLocalObjectReference | SecretRef holds the name of a secret that contains the Helm credentials.
The secret must contain a |
KluctlDeployment
KluctlDeployment is the Schema for the kluctldeployments API
| Field | Description | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta | Refer to the Kubernetes API documentation for the fields of the
metadata field. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
specKluctlDeploymentSpec |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
statusKluctlDeploymentStatus |
KluctlDeploymentSpec
(Appears on: KluctlDeployment)
| Field | Description |
|---|---|
sourceProjectSource | Specifies the project source location |
sourceOverrides[]SourceOverride | (Optional) Specifies source overrides |
credentialsProjectCredentials | (Optional) Credentials specifies the credentials used when pulling sources |
decryptionDecryption | (Optional) Decrypt Kubernetes secrets before applying them on the cluster. |
intervalKubernetes meta/v1.Duration | The interval at which to reconcile the KluctlDeployment. Reconciliation means that the deployment is fully rendered and only deployed when the result changes compared to the last deployment. To override this behavior, set the DeployInterval value. |
retryIntervalKubernetes meta/v1.Duration | (Optional) The interval at which to retry a previously failed reconciliation. When not specified, the controller uses the Interval value to retry failures. |
deployIntervalSafeDuration | (Optional) DeployInterval specifies the interval at which to deploy the KluctlDeployment, even in cases the rendered result does not change. |
validateIntervalSafeDuration | (Optional) ValidateInterval specifies the interval at which to validate the KluctlDeployment.
Validation is performed the same way as with ‘kluctl validate -t |
timeoutKubernetes meta/v1.Duration | (Optional) Timeout for all operations. Defaults to ‘Interval’ duration. |
suspendbool | (Optional) This flag tells the controller to suspend subsequent kluctl executions, it does not apply to already started executions. Defaults to false. |
helmCredentials[]HelmCredentials | (Optional) HelmCredentials is a list of Helm credentials used when non pre-pulled Helm Charts are used inside a Kluctl deployment. DEPRECATED this field is deprecated and setting will result in errors. It will be removed in the next API version bump. Use spec.credentials.helm instead. |
serviceAccountNamestring | (Optional) The name of the Kubernetes service account to use while deploying. If not specified, the default service account is used. |
kubeConfigKubeConfig | (Optional) The KubeConfig for deploying to the target cluster. Specifies the kubeconfig to be used when invoking kluctl. Contexts in this kubeconfig must match the context found in the kluctl target. As an alternative, specify the context to be used via ‘context’ |
targetstring | (Optional) Target specifies the kluctl target to deploy. If not specified, an empty target is used that has no name and no context. Use ‘TargetName’ and ‘Context’ to specify the name and context in that case. |
targetNameOverridestring | (Optional) TargetNameOverride sets or overrides the target name. This is especially useful when deployment without a target. |
contextstring | (Optional) If specified, overrides the context to be used. This will effectively make kluctl ignore the context specified in the target. |
argsk8s.io/apimachinery/pkg/runtime.RawExtension | (Optional) Args specifies dynamic target args. |
images[]github.com/kluctl/kluctl/v2/pkg/types.FixedImage | (Optional) Images contains a list of fixed image overrides. Equivalent to using ‘–fixed-images-file’ when calling kluctl. |
dryRunbool | (Optional) DryRun instructs kluctl to run everything in dry-run mode. Equivalent to using ‘–dry-run’ when calling kluctl. |
noWaitbool | (Optional) NoWait instructs kluctl to not wait for any resources to become ready, including hooks. Equivalent to using ‘–no-wait’ when calling kluctl. |
forceApplybool | (Optional) ForceApply instructs kluctl to force-apply in case of SSA conflicts. Equivalent to using ‘–force-apply’ when calling kluctl. |
replaceOnErrorbool | (Optional) ReplaceOnError instructs kluctl to replace resources on error. Equivalent to using ‘–replace-on-error’ when calling kluctl. |
forceReplaceOnErrorbool | (Optional) ForceReplaceOnError instructs kluctl to force-replace resources in case a normal replace fails. Equivalent to using ‘–force-replace-on-error’ when calling kluctl. |
abortOnErrorbool | (Optional) ForceReplaceOnError instructs kluctl to abort deployments immediately when something fails. Equivalent to using ‘–abort-on-error’ when calling kluctl. |
includeTags[]string | (Optional) IncludeTags instructs kluctl to only include deployments with given tags. Equivalent to using ‘–include-tag’ when calling kluctl. |
excludeTags[]string | (Optional) ExcludeTags instructs kluctl to exclude deployments with given tags. Equivalent to using ‘–exclude-tag’ when calling kluctl. |
includeDeploymentDirs[]string | (Optional) IncludeDeploymentDirs instructs kluctl to only include deployments with the given dir. Equivalent to using ‘–include-deployment-dir’ when calling kluctl. |
excludeDeploymentDirs[]string | (Optional) ExcludeDeploymentDirs instructs kluctl to exclude deployments with the given dir. Equivalent to using ‘–exclude-deployment-dir’ when calling kluctl. |
deployModestring | (Optional) DeployMode specifies what deploy mode should be used. The options ‘full-deploy’ and ‘poke-images’ are supported. With the ‘poke-images’ option, only images are patched into the target without performing a full deployment. |
validatebool | (Optional) Validate enables validation after deploying |
prunebool | (Optional) Prune enables pruning after deploying. |
deletebool | (Optional) Delete enables deletion of the specified target when the KluctlDeployment object gets deleted. |
manualbool | (Optional) Manual enables manual deployments, meaning that the deployment will initially start as a dry run deployment and only after manual approval cause a real deployment |
manualObjectsHashstring | (Optional) ManualObjectsHash specifies the rendered objects hash that is approved for manual deployment. If Manual is set to true, the controller will skip deployments when the current reconciliation loops calculated objects hash does not match this value. There are two ways to use this value properly. 1. Set it manually to the value found in status.lastObjectsHash. 2. Use the Kluctl Webui to manually approve a deployment, which will set this field appropriately. |
KluctlDeploymentStatus
(Appears on: KluctlDeployment)
KluctlDeploymentStatus defines the observed state of KluctlDeployment
| Field | Description |
|---|---|
reconcileRequestResultManualRequestResult | (Optional) |
diffRequestResultManualRequestResult | (Optional) |
deployRequestResultManualRequestResult | (Optional) |
pruneRequestResultManualRequestResult | (Optional) |
validateRequestResultManualRequestResult | (Optional) |
observedGenerationint64 | (Optional) ObservedGeneration is the last reconciled generation. |
observedCommitstring | ObservedCommit is the last commit observed |
conditions[]Kubernetes meta/v1.Condition | (Optional) |
projectKeygithub.com/kluctl/kluctl/lib/git/types.ProjectKey | (Optional) |
targetKeygithub.com/kluctl/kluctl/v2/pkg/types/result.TargetKey | (Optional) |
lastObjectsHashstring | (Optional) |
lastManualObjectsHashstring | (Optional) |
lastPrepareErrorstring | (Optional) |
lastDiffResultk8s.io/apimachinery/pkg/runtime.RawExtension | (Optional) LastDiffResult is the result summary of the last diff command |
lastDeployResultk8s.io/apimachinery/pkg/runtime.RawExtension | (Optional) LastDeployResult is the result summary of the last deploy command |
lastValidateResultk8s.io/apimachinery/pkg/runtime.RawExtension | (Optional) LastValidateResult is the result summary of the last validate command |
lastDriftDetectionResultk8s.io/apimachinery/pkg/runtime.RawExtension | LastDriftDetectionResult is the result of the last drift detection command optional |
lastDriftDetectionResultMessagestring | LastDriftDetectionResultMessage contains a short message that describes the drift optional |
KubeConfig
(Appears on: KluctlDeploymentSpec)
KubeConfig references a Kubernetes secret that contains a kubeconfig file.
| Field | Description |
|---|---|
secretRefSecretKeyReference | SecretRef holds the name of a secret that contains a key with
the kubeconfig file as the value. If no key is set, the key will default
to ‘value’. The secret must be in the same namespace as
the Kustomization.
It is recommended that the kubeconfig is self-contained, and the secret
is regularly updated if credentials such as a cloud-access-token expire.
Cloud specific |
LocalObjectReference
(Appears on: Decryption, HelmCredentials, ProjectCredentialsGit, ProjectCredentialsHelm, ProjectCredentialsOci)
| Field | Description |
|---|---|
namestring | Name of the referent. |
ManualRequest
(Appears on: ManualRequestResult)
ManualRequest is used in json form inside the manual request annotations
| Field | Description |
|---|---|
requestValuestring | |
overridesPatchk8s.io/apimachinery/pkg/runtime.RawExtension | (Optional) |
ManualRequestResult
(Appears on: KluctlDeploymentStatus)
| Field | Description |
|---|---|
requestManualRequest | |
startTimeKubernetes meta/v1.Time | |
endTimeKubernetes meta/v1.Time | (Optional) |
reconcileIdstring | |
resultIdstring | (Optional) |
commandErrorstring | (Optional) |
ProjectCredentials
(Appears on: KluctlDeploymentSpec)
| Field | Description |
|---|---|
git[]ProjectCredentialsGit | (Optional) Git specifies a list of git credentials |
oci[]ProjectCredentialsOci | (Optional) Oci specifies a list of OCI credentials |
helm[]ProjectCredentialsHelm | (Optional) Helm specifies a list of Helm credentials |
ProjectCredentialsGit
(Appears on: ProjectCredentials)
| Field | Description |
|---|---|
hoststring | Host specifies the hostname that this secret applies to. If set to ‘’, this set of credentials applies to all hosts. Using ‘’ for http(s) based repositories is not supported, meaning that such credentials sets will be ignored. You must always set a proper hostname in that case. |
pathstring | (Optional) Path specifies the path to be used to filter Git repositories. The path can contain wildcards. These credentials will only be used for matching Git URLs. If omitted, all repositories are considered to match. |
secretRefLocalObjectReference | SecretRef specifies the Secret containing authentication credentials for the git repository. For HTTPS git repositories the Secret must contain ‘username’ and ‘password’ fields. For SSH git repositories the Secret must contain ‘identity’ and ‘known_hosts’ fields. |
ProjectCredentialsHelm
(Appears on: ProjectCredentials)
| Field | Description |
|---|---|
hoststring | Host specifies the hostname that this secret applies to. |
pathstring | (Optional) Path specifies the path to be used to filter Helm urls. The path can contain wildcards. These credentials will only be used for matching URLs. If omitted, all URLs are considered to match. |
secretRefLocalObjectReference | SecretRef specifies the Secret containing authentication credentials for
the Helm repository.
The secret can either container basic authentication credentials via |
ProjectCredentialsOci
(Appears on: ProjectCredentials)
| Field | Description |
|---|---|
registrystring | Registry specifies the hostname that this secret applies to. |
repositorystring | (Optional) Repository specifies the org and repo name in the format ‘org-name/repo-name’. Both ‘org-name’ and ‘repo-name’ can be specified as ‘*’, meaning that all names are matched. |
secretRefLocalObjectReference | SecretRef specifies the Secret containing authentication credentials for the oci repository. The secret must contain ‘username’ and ‘password’. |
ProjectSource
(Appears on: KluctlDeploymentSpec)
| Field | Description |
|---|---|
gitProjectSourceGit | (Optional) Git specifies a git repository as project source |
ociProjectSourceOci | (Optional) Oci specifies an OCI repository as project source |
urlstring | (Optional) Url specifies the Git url where the project source is located DEPRECATED this field is deprecated and will be removed in the next API version bump. Use spec.source.git.url instead. |
refgithub.com/kluctl/kluctl/lib/git/types.GitRef | (Optional) Ref specifies the branch, tag or commit that should be used. If omitted, the default branch of the repo is used. DEPRECATED this field is deprecated and will be removed in the next API version bump. Use spec.source.git.ref instead. |
pathstring | (Optional) Path specifies the sub-directory to be used as project directory DEPRECATED this field is deprecated and will be removed in the next API version bump. Use spec.source.git.path instead. |
secretRefk8s.io/apimachinery/pkg/runtime.RawExtension | SecretRef specifies the Secret containing authentication credentials for See ProjectSourceCredentials.SecretRef for details DEPRECATED this field is deprecated and will cause errors on reconciliation. It will be removed in the next API version bump. Use spec.credentials.git instead. |
credentials[]k8s.io/apimachinery/pkg/runtime.RawExtension | (Optional) Credentials specifies a list of secrets with credentials DEPRECATED this field is deprecated and will cause errors on reconciliation. It will be removed in the next API version bump. Use spec.credentials.git instead. |
ProjectSourceGit
(Appears on: ProjectSource)
| Field | Description |
|---|---|
urlstring | URL specifies the Git url where the project source is located. If the given Git repository needs authentication, use spec.credentials.git to specify those. |
refgithub.com/kluctl/kluctl/lib/git/types.GitRef | (Optional) Ref specifies the branch, tag or commit that should be used. If omitted, the default branch of the repo is used. |
pathstring | (Optional) Path specifies the sub-directory to be used as project directory |
ProjectSourceOci
(Appears on: ProjectSource)
| Field | Description |
|---|---|
urlstring | Url specifies the Git url where the project source is located. If the given OCI repository needs authentication, use spec.credentials.oci to specify those. |
refgithub.com/kluctl/kluctl/v2/pkg/types.OciRef | (Optional) Ref specifies the tag to be used. If omitted, the “latest” tag is used. |
pathstring | (Optional) Path specifies the sub-directory to be used as project directory |
SafeDuration
(Appears on: KluctlDeploymentSpec)
| Field | Description |
|---|---|
DurationKubernetes meta/v1.Duration |
SecretKeyReference
(Appears on: KubeConfig)
SecretKeyReference contains enough information to locate the referenced Kubernetes Secret object in the same namespace. Optionally a key can be specified. Use this type instead of core/v1 SecretKeySelector when the Key is optional and the Optional field is not applicable.
| Field | Description |
|---|---|
namestring | Name of the Secret. |
keystring | (Optional) Key in the Secret, when not specified an implementation-specific default key is used. |
SourceOverride
(Appears on: KluctlDeploymentSpec)
| Field | Description |
|---|---|
repoKeygithub.com/kluctl/kluctl/lib/git/types.RepoKey | |
urlstring | |
isGroupbool | (Optional) |
This page was automatically generated with gen-crd-api-reference-docs
3 - Kluctl Webui
The Kluctl Webui is a powerful UI which allows you to monitor and control your Kluctl GitOps deployments.
You can run it locally or install it to your Kubernetes cluster.
State of the Webui
Please note that the Kluctl Webui is still in early stage of development, missing many planned features. It might also contain bugs and be unstable in some situations. If you encounter any such problems, please report these to https://github.com/kluctl/kluctl/issues.
Screenshots
Targets Overview
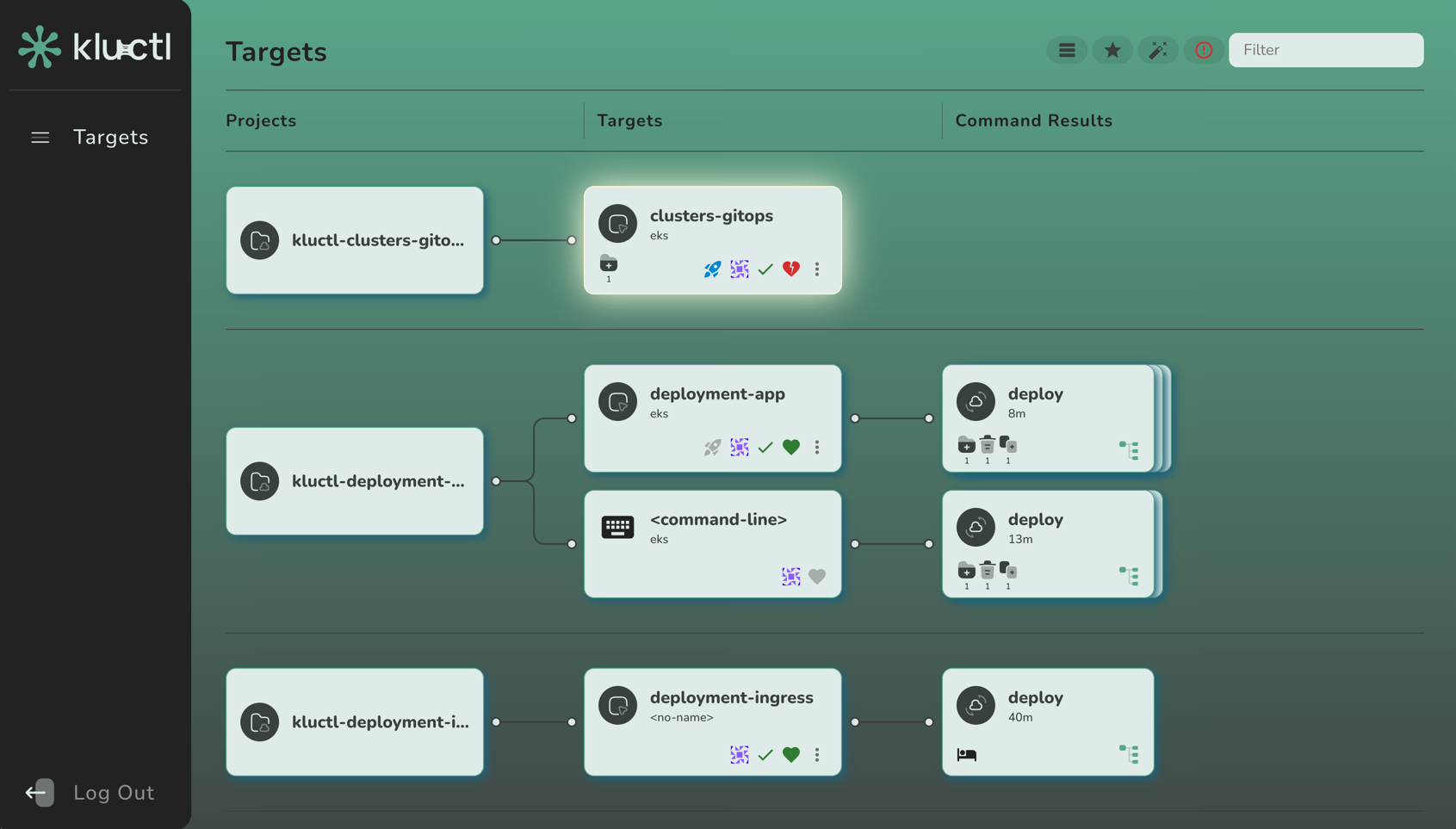
Command Result
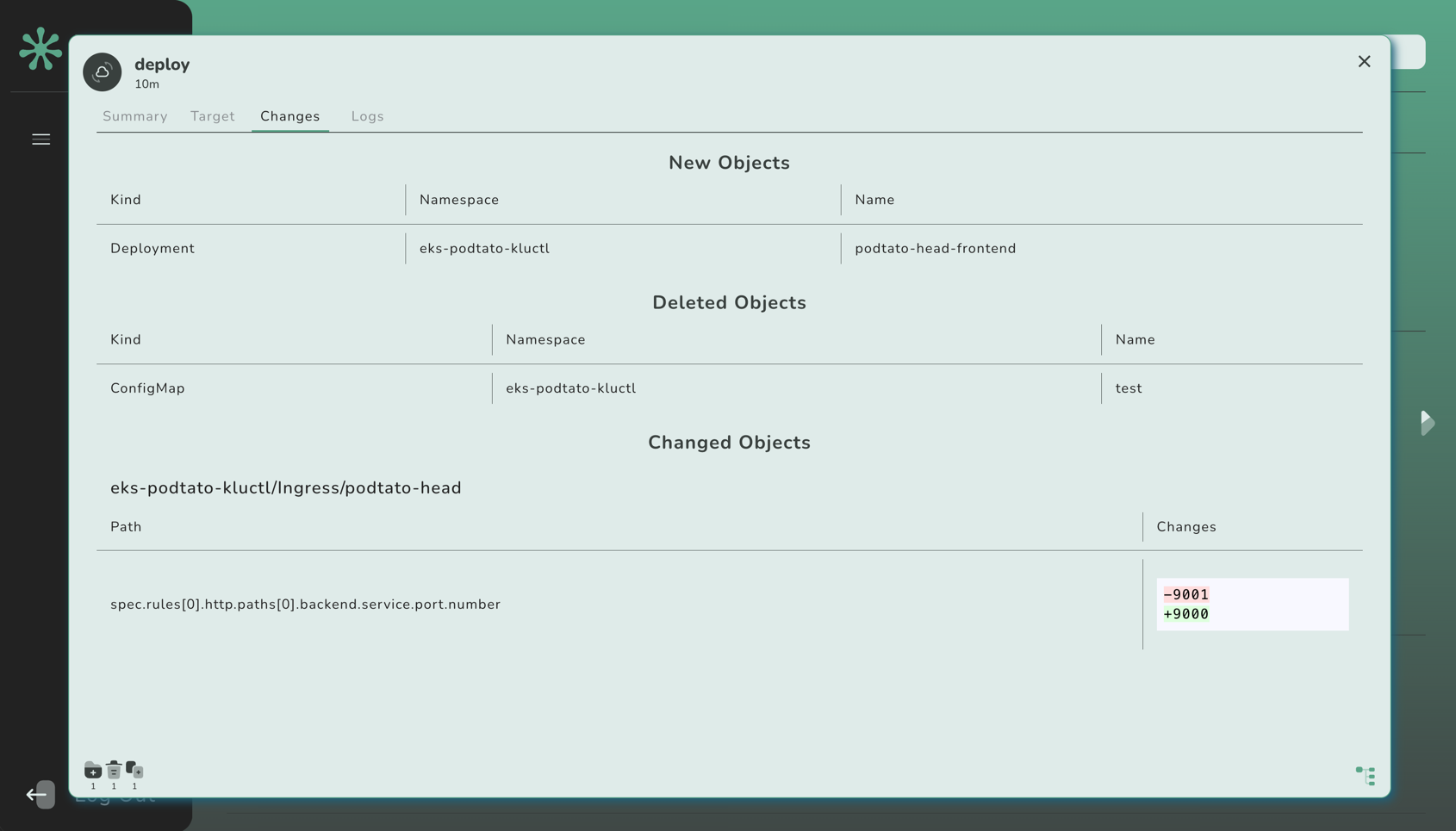
3.1 - Installation
The Kluctl Webui can be installed by using a Git Include that refers to the webui deployment project.
Example:
deployments:
- git:
url: https://github.com/kluctl/kluctl.git
subDir: install/webui
ref:
tag: v2.28.1
Login
Static Users
By default, the Webui will automatically generate an static credentials for an admin and for a viewer user. These
credentials can be extracted from the kluctl-system/webui-secret Secret after the Webui has started up for the first
time.
To get the admin password, invoke:
$ kubectl -n kluctl-system get secret webui-secret -o jsonpath='{.data.admin-password}' | base64 -d
For the viewer password, invoke:
$ kubectl -n kluctl-system get secret webui-secret -o jsonpath='{.data.viewer-password}' | base64 -d
If you do not want to rely on the Webui to generate those secrets, simply use your typical means of creating/updating
the webui-secret Secret. The secret must contain values for admin-password, viewer-password.
OIDC Integration
The Webui offers an OIDC integration, which can be configured via CLI arguments.
For an example of an OIDC provider configurations, see Azure AD Integration.
Customization
Serving under a different path
By default, the webui is served under the /path. To change the path, pass the --prefix-path argument to the webui:
deployments:
- git:
url: https://github.com/kluctl/kluctl.git
subDir: install/webui
ref:
tag: v2.28.1
vars:
- values:
webui_args:
- --path-prefix=/my-custom-prefix
Overriding the version
The image version of the Webui can be overriden with the kluctl_version arg:
deployments:
- git:
url: https://github.com/kluctl/kluctl.git
subDir: install/webui
ref:
tag: main
vars:
- values:
args:
kluctl_version: v2.28.1
Passing arguments
You can pass arbitrary command line arguments to the webui by providing the webui_args arg:
deployments:
- git:
url: https://github.com/kluctl/kluctl.git
subDir: install/webui
ref:
tag: v2.28.1
vars:
- values:
webui_args:
- --gops-agent
3.2 - Running locally
The Kluctl Webui can be run locally by simply invoking kluctl webui run.
It will by default connect to your local Kubeconfig Context and expose the Webui on localhost. It will also open
the browser for you.
Multiple Clusters
The Webui can already handle multiple clusters. Simply pass --context <context-name> multiple times to kluctl webui run.
This will cause the Webui to listen for status updates on all passed clusters.
As noted in State of the Webui, the Webui is still in early stage and thus currently lacks sorting and filtering for clusters. This will be implemented in future releases.
3.3 - Azure AD Integration
Azure AD can be integrated via the OIDC integration.
Configure a new Azure AD App registration
Add a new Azure AD App registration
- From the
Azure Active Directory>App registrationsmenu, choose+ New registration - Enter a
Namefor the application (e.g.Kluctl Webui). - Specify who can use the application (e.g.
Accounts in this organizational directory only). - Enter Redirect URI (optional) as follows (replacing
my-kluctl-webui-urlwith your Kluctl Webui URL), then chooseAdd.- Platform:
Web - Redirect URI: https://
<my-kluctl-webui-url>/auth/callback
- Platform:
- When registration finishes, the Azure portal displays the app registration’s Overview pane. You see the Application (client) ID.

Add credentials a new Azure AD App registration
- From the
Certificates & secretsmenu, choose+ New client secret - Enter a
Namefor the secret (e.g.Kluctl Webui SSO).- Make sure to copy and save generated value. This is a value for the
oidc-client-secret.
- Make sure to copy and save generated value. This is a value for the
Setup permissions for Azure AD Application
- From the
API permissionsmenu, choose+ Add a permission - Find
User.Readpermission (underMicrosoft Graph) and grant it to the created application:
- From the
Token Configurationmenu, choose+ Add groups claim
Associate an Azure AD group to your Azure AD App registration
- From the
Azure Active Directory>Enterprise applicationsmenu, search the App that you created (e.g.Kluctl Webui).- An Enterprise application with the same name of the Azure AD App registration is created when you add a new Azure AD App registration.
- From the
Users and groupsmenu of the app, add any users or groups requiring access to the service.
Configure the Kluctl Webui to use the new Azure AD App registration
Use the following configuration when installing the Webui. Replace occurrences of
<directory_tenant_id>, <client_id>, <my-kluctl-webui-url> and <admin_group_id> with the appropriate values from
above.
deployments:
- path: secrets
- git:
url: https://github.com/kluctl/kluctl.git
subDir: install/webui
ref:
tag: v2.28.1
vars:
- values:
args:
webui_args:
- --auth-oidc-issuer-url=https://login.microsoftonline.com/<directory_tenant_id>/v2.0
- --auth-oidc-client-id=<client_id>
- --auth-oidc-scope=openid
- --auth-oidc-scope=profile
- --auth-oidc-scope=email
- --auth-oidc-redirect-url=https://<my-kluctl-webui-url>/auth/callback
- --auth-oidc-group-claim=groups
- --auth-oidc-admins-group=<admin_group_id>
Also, add webui-secrets.yaml inside the secrets subdirectory:
apiVersion: v1
kind: Secret
metadata:
name: webui-secret
namespace: kluctl-system
stringData:
oidc-client-secret: "<client_secret>"
Please note that the client secret is sensitive data and should not be added unencrypted to you git repository. Consider encrypting it via SOPS.
4 - Kluctl Recipes
This is a collection of recipes, targeted at developers, devops engineers, SREs and everyone else who wants to use Kluctl to deploy their workloads to Kubernetes.
These recipes try to describe how to implement common use cases tasks.
4.1 - Deploying multiple times
This recipe will guide you on how to deploy the same deployment multiple times to the same (via namespaces) or different clusters.
Use specific targets
The easiest way to achieve this is to define targets in
your .kluctl.yaml. Each target should then use args to define
a small set configuration values for the specific target.
Each target should relate to the target environment and/or cluster that it needs to be deployed to. For example, one
could be named prod while another is named test, meaning that you can either deploy to the prod or to the test
environment. It’s also useful to set the context field
on each target, so that you can’t accidentally deploy the prod target to the test cluster.
args should be minimalistic to avoid bloating up the .kluctl.yaml. It should be used as the “entrypoint” into
the actual configuration, which is then loaded from inside the root deployment.yaml
via vars. See advanced configuration for details on this.
Example targets definition:
targets:
- name: prod
context: prod.example.com
args:
environment_name: prod
- name: test
context: test.example.com
args:
environment_name: test
# Warning, this discriminator is only ok if targets are only deployed once per cluster. See next chapter for details.
discriminator: "my-project-{{ target.name }}"
args:
- name: environment_name
Example CLI invocations:
$ kluctl deploy -t prod
$ kluctl deploy -t test
Use more dynamic targets
As an alternative to very specific targets, you could also define targets that are more dynamic so that each target can
be deployed multiple times, but to different Kubernetes contexts or even namespaces. You can also mix such targets,
for example have one prod target that is just like described in the previous chapter, and one non-prod target
that can be used to deploy to multiple non-production clusters.
The dynamic targets then need a way so that they can be differentiated. The easiest way is to use different contexts,
which means you deploy it to different clusters. Another way is to introduce args that serve to differentiate, e.g.
an arg names environment_name which can then be used to deploy the same workloads to different namespaces, add prefixes
to global resources, create unique ingresses, and so on.
If such an argument is introduced, you would then invoke the CLI with the argument being set.
Another thing to take into account is the required uniqueness of discriminators to make delete and prune work properly. If you miss this crucial part or make a mistake, you might end up deleting resources that were not meant to be deleted. The uniqueness must be ensured inside the boundaries of individual clusters.
Example targets definition:
targets:
- name: prod
context: prod.example.com
args:
environment_type: prod
environment_name: prod
- name: non-prod
args:
environment_type: non-prod
# environment_name must be passed via CLI
# This will ensure that the discriminator is unique, even if the same target is deployed multiple times
discriminator: my-project-{{ target.name }}-{{ args.environment_type }}-{{ args.environment_name }}
# This is a bad example of a discriminator. It will lead to the discriminator being equal for every environment deployed to the same cluster.
# discriminator: "my-project-{{ target.name }}"
args:
- name: environment_type
- name: environment_name
Example CLI invocations:
$ kluctl deploy -t prod # deploys to prod context
$ kluctl deploy -t non-prod -a environment_name=test-env1 # deploys to currently active context
$ kluctl deploy -t non-prod -a environment_name=test-env2 # deploys to currently active context
$ kluctl deploy -t non-prod -a environment_name=test-env3 --context test2.exmaple.com
Too long discriminators
Right now, Kluctl is internally using a single label to store discriminators in Kubernetes. This has some serious limitations in regard to the length of the discriminators, which is 63 characters. This means, that the discriminator template shown in the above example can easily lead to errors. This issue will be fixed when https://github.com/kluctl/kluctl/issues/468 is implemented.
Until then, you might need to use some form of shortening, e.g. by using a shortened hash of some string. Example for this:
discriminator: my-project-{{ target.name }}-{{ args.environment_type }}-{{ (args.environment_name | sha256)[:8] }}
Using namespaces and more
So far, we have only shown how to define and use the targets feature to implement multiple target environments.
This works out-of-the-box when you target different clusters per target, but will need some additional work when
deploying to the same cluster. In that case, you are required to use different namespaces for each environment.
This can be easily achieved by using the mentioned environment_name inside resources. Combined with templating, it can
be used to create dynamic namespaces, prefix resource names and create unique ingresses.
Example project:
my-project/
├── .kluctl.yaml
├── deployment.yaml
├── namespaces/
│ └── namespace.yaml
└── apps
├── deployment.yaml
├── app1/
│ ├── resource1.yaml
│ └── resource2.yaml
└── app2/
├── resource1.yaml
└── resource2.yaml
.kluctl.yaml
See above.
deployment.yaml
deployments:
- path: namespaces
- barrier: true # ensure namespaces are applied before we continue
- include: apps
namespaces/namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: {{ args.environment_name }}
apps/deployment.yaml
deployments:
- path: app1
- path: app2
# This instructs Kluctl to set the specified namespace on all resources, including resources from `app1` and `app2`,
# that do not have a namespace set explicitly.
overrideNamespace: {{ args.environment_name }}
apps/app1/resource1.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: my-cm
# no namespace needed here, as it is set via the `overrideNamespace` from `apps/deployment.yaml`
data:
# just an example to show that you can also use the `args` here.
environment_name: {{ args.environment_name }}
4.2 - Advanced configuration
This recipe will try to give best practices on how to achieve advanced configuration that keeps being maintainable.
Args as entrypoint
Kluctl offers multiple ways to introduce configuration args into your deployment. These are all accessible via
templating by referencing the global args variable, e.g. {{ args.my_arg }}.
Args can be passed via command line arguments, target definitions and GitOps KluctlDeployment spec.
It might however be tempting to provide all necessary configuration via args, which can easily end up clogging things up in a very unmaintainable way.
Combining args with vars sources
The better and much more maintainable approach is to combine args with
variable sources. You could for example
introduce an arg that is later used to load further configuration from YAML files or even external vars sources (e.g. git).
Consider the following example:
# .kluctl.yaml
targets:
- name: prod
context: prod.example.com
args:
environment_type: prod
environment_name: prod
- name: test
context: test.example.com
args:
environment_type: non-prod
environment_name: test
- name: dev
context: test.example.com
args:
environment_type: non-prod
environment_name: dev
# root deployment.yaml
vars:
- file: config/{{ args.environment_type }}.yaml
deployments:
- include: my-include
- path: my-deployment
The above deployment.yaml will load different configuration, depending on the passed environment_type argument.
This means, you’ll also need the following configuration files:
# config/prod.yaml
myApp:
replicas: 3
# config/non-prod.yaml
myApp:
replicas: 1
This way, you don’t have to bloat up the .kluctl.yaml with some ever-growing amount of configuration but instead can
move such configuration into dedicated configuration files.
The resulting configuration can then be used via templating, e.g. {{ myApp.replicas }}
Layering configuration on top of each other
Kluctl merges already loaded configuration with freshly loaded configuration. It does this for every item in vars.
At the same time, Kluctl allows to use templating with the previously loaded configuration context in each loaded
vars source. This means, that configuration that was loaded by a vars item before the current one can already be used
in the current one.
All deployment items will then be provided with the final merged configuration. If deployment items also define vars, these are merged as well, but only for the context of the specific deployment item.
Consider the following example:
# root deployment.yaml
vars:
- file: config/common.yaml
- file: config/{{ args.environment_type }}.yaml
- file: config/monitoring.yaml
# config/common.yaml
myApp:
monitoring:
enabled: false
# config/prod.yaml
myApp:
replicas: 3
monitoring:
enabled: true
# config/non-prod.yaml
myApp:
replicas: 1
The merged configuration for prod environments will have myApp.monitoring.enabled set to true, while all other
environments will have it set to false.
Putting configuration into the target cluster
Kluctl supports many different variable sources, which means you are not forced to store all configuration in files which are part of the project.
You can also store configuration inside the target cluster and access this configuration via the clusterConfigMap or clusterSecret variable sources. This configuration could for example be part of the cluster provisioning stage and contain information about networking info, cloud info, DNS info, and so on, so that this can then be re-used wherever needed (e.g. in ingresses).
Consider the following example ConfigMap, which was already deployed to your target cluster:
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-info
namespace: kube-system
data:
vars: |
clusterInfo:
baseDns: test.example.com
aws:
accountId: 12345
irsaPrefix: test-example-com
Your deployment:
# root deployment.yaml
vars:
- clusterConfigMap:
name: cluster-info
namespace: kube-system
key: vars
- file: ... # some other configuration, as usual
deployments:
# as usual
- ...
# some/example/ingress.yaml
# look at the DNS name
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
namespace: my-namespace
spec:
rules:
- host: my-ingress.{{ clusterInfo.baseDns }}
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: my-service
port:
number: 80
tls:
- hosts:
- 'my-ingress.{{ clusterInfo.baseDns }}'
secretName: 'ssl-cert'
# some/example/irso-service-account.yaml
# Assuming you're using IRSA (https://docs.aws.amazon.com/eks/latest/userguide/iam-roles-for-service-accounts.html)
# for external-dns
apiVersion: v1
kind: ServiceAccount
metadata:
name: external-dns
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::{{ clusterInfo.aws.accountId }}:role/{{ clusterInfo.aws.irsaPrefix }}-external-dns
4.3 - Deploying via GitOps
This recipe will try to give best practices on how to leverage the kluctl controller to implement Kluctl GitOps. Before exploring Kluctl GitOps, it is suggested to first learn how Kluctl works without GitOps being involved.
You should also try to understand how to deploy to multiple targets/environments first to get a basic understanding of how the same deployment project can be deployed multiple times.
The source shown in this recipe can also be found on GitHub in the kluctl-examples repository
GitOps is optional
Kluctl follows a command-line-first approach, which means that all features implemented into Kluctl will always be added in a way so that you can keep using the CLI. This means, that Kluctl does not depend on the controller to implement all its features.
Letting the controller take over is optional and can even be done in a way so that you can mix CLI based (push-based GitOps) approaches and controller based approaches (pull-based GitOps).
GitOps is just an interface
Kluctl considers GitOps as just another interface for your deployments. This means that everything that can be
performed and configured via the CLI can also be configured through the Kluctl CRDs
(KluctlDeployment).
Consider a deployment project that you usually deploy via these commands:
$ git clone https://github.com/kluctl/kluctl-examples.git
$ cd simple
$ kluctl deploy -t simple -a environment=test
The above lines perform a deployment in the “push” style, meaning that you (or your CI) pushes the deployment to the target cluster. That same deployment project can also be deployed in “pull” style, which involves the kluctl-controller running on the target cluster that “pulls” the deployment into the cluster.
If you have the controller already installed, you can apply the following
KluctlDeployment to your target cluster:
# file example-deployment.yaml
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: example-deployment
namespace: kluctl-system
spec:
interval: 5m
source:
git:
url: https://github.com/kluctl/kluctl-examples.git
path: simple
target: simple
args:
environment: test
context: default
The above manifest can be applied via plain kubectl apply -f example-deployment.yaml or via a Kluctl deployment
project. Later sections will go into more detail about some possible options.
After the KluctlDeployment got applied, the controller will periodically (5m interval) clone the repository and check
if the result of the rendering process differs since the last deployment. If it differs, the controller will deploy
the deployment project with the given options (which are equal to options of the CLI example from above).
The reconciliation loop
After a KluctlDeployment is applied to the cluster, the kluctl-controller will immediately pick up that deployment
and start to periodically reconcile the deployment. Reconciliation basically performs the following steps:
- Clone the referenced source (don’t worry, this fast due to internal caching)
- Render the deployment with all the provided options (target, args, …)
- Check if the rendered result has changed since the last performed deployment
- If it has not changed, sleep for the duration specified via
intervaland then repeat the reconciliation loop - If it has changed, perform a deployment and record the deployment result in the cluster (this can then be used via the Kluctl Webui)
- Sleep for the duration specified via
intervaland then repeat the reconciliation loop
If you already know GitOps from other solutions (e.g. Flux), you might notice that Kluctl does not deploy on every reconciliation iteration but instead only when the source changes. This deviation from other GitOps solutions is intended as it enabled more flexible intervention and processes (e.g, mixing GitOps with push-based processes).
To mitigate drift between the source and the cluster state, drift detection is performed on every reconciliation iteration. If necessary, the drift can be viewed and fixed via the Kluctl Webui or via the GitOps commands.
You can also override this behavior to match the behavior of other GitOps solutions by using deployInterval, which will cause the reconciliation loop to periodically perform a deployment even if the source does not change.
Starting with Kluctl GitOps
To start using Kluctl GitOps, install it into your cluster first.
Optionally, if you want to use the Kluctl Webui to monitor and control your GitOps deployments, either run it locally or install it into the cluster.
Managing GitOps deployments
KluctlDeployment resources need to be applied and managed the same way as any other Kubernetes resource. You might
easily end up managing dozens or even hundreds of KluctlDeployments per cluster. The recommended way to do this is
to introduce a dedicated GitOps deployment project which is only responsible for the management of other deployments.
Other options exist as well, it’s for example also possible to include the KluctlDeployment resource into the
deployment itself, so when you perform the initial deployment, you will automatically let GitOps take over. The following
sections will go into more detail.
Dedicated GitOps deployment project
In this setup, you’ll have one dedicated directory (a simple deployment item)
for each cluster. These deployment items will contain one or more KluctlDeployment resources.
The deployment works by using a simple templated entry in deployments which uses the argument cluster_name so that
a different directory is loaded for each cluster.
An clusters/all deployment item is loaded as well for each cluster. The clusters/all deployment item is meant to
add common deployments that are needed on all clusters. One of these deployments is the GitOps deployment itself, so
that it is also managed via GitOps.
The namespaces deployment item is used to create the kluctl-gitops namespace which we then use to deploy the
KluctlDeployment resources into. It’s generally best practice to use a dedicated namespace for GitOps.
Project structure
Consider the following project structure:
gitops-deployment
├── namespaces
│ └── kluctl-gitops.yaml
├── clusters/
│ ├── test.example.com/
│ │ ├── app1.yaml
│ │ └── app2.yaml
│ ├── prod.example.com/
│ │ ├── app1.yaml
│ │ └── app2.yaml
│ ├── all/
│ │ └── gitops.yaml
│ └── deployment.yaml
├── .kluctl.yaml
└── deployment.yaml
And the following YAML files and manifests:
# .kluctl.yaml
args:
# This allows us to deploy the GitOps deployment to different clusters. It is used to include dedicated deployment
# items for the selected cluster.
- name: cluster_name
targets:
- name: gitops
# Without a discriminator, pruning won't work. Make sure the rendered result is unique on the target cluster
discriminator: gitops-{{ args.cluster_name | slugify }}
# deployment.yaml
deployments:
- path: namespaces
- barrier: true
- include: clusters
# clusters/deployment.yaml
deployments:
# Include things that are required on all clusters (e.g., the KluctlDeployment for the GitOps deployment itself)
- path: all
# We use simple templating to change a dedicated deployment item per cluster
- path: {{ args.cluster_name }}
# namespaces/kluctl-gitops.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kluctl-gitops
# clusters/test.example.com/app1.yaml
# and clusters/prod.example.com/app1.yaml
# but with adjusted specs (e.g., environment names differ)
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: app1
namespace: kluctl-gitops
spec:
interval: 5m
source:
git:
url: https://github.com/kluctl/kluctl-examples.git
path: simple
target: simple
args:
environment: test
context: default
# Let it automatically clean up orphan resources and delete all resources when the KluctlDeployment itself gets
# deleted. You might consider setting these to false for prod and instead do manual pruning and deletion when the
# need arises.
prune: true
delete: true
# clusters/test.example.com/app2.yaml
# and clusters/prod.example.com/app2.yaml
# but with adjusted specs (e.g., environment names differ)
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: app2
namespace: kluctl-gitops
spec:
interval: 5m
source:
git:
url: https://github.com/kluctl/kluctl-examples.git
path: simple-helm
target: simple-helm
args:
environment: test
context: default
# Let it automatically clean up orphan resources and delete all resources when the KluctlDeployment itself gets
# deleted. You might consider setting these to false for prod and instead do manual pruning and deletion when the
# need arises.
prune: true
delete: true
# clusters/all/gitops.yaml
apiVersion: gitops.kluctl.io/v1beta1
kind: KluctlDeployment
metadata:
name: gitops
namespace: kluctl-gitops
spec:
interval: 5m
source:
git:
url: https://github.com/kluctl/kluctl-examples.git
path: gitops-deployment # You could also use a dedicated repository without a sub-directory
target: gitops
args:
# this passes the cluster_name initially passed via `kluctl deploy -a cluster_name=xxx.example.com` into the KluctlDeployment
cluster_name: {{ args.cluster_name }}
context: default
# let it automatically clean up orphan KluctlDeployment resources
prune: true
delete: true
Git/Helm/OCI authentication
Please note that the above example deployments do not require authentication. It’s very likely that you’d need authentication for Git repositories, Helm repositories or OCI registries in your own setup, simply because not everything is public and/or Open Source.
To add authentication for the KluctlDeployments, fill the
credentials field in the spec of the
KluctlDeployments. These credentials refer to Secrets which also need to be deployed to the cluster.
You can either provide these secrets manually (should be avoided), via SOPS
encrypted Secrets (which can then be part of the GitOps deployment project itself) or via
External Secrets.
Managing the GitOps deployment project
Please ensure that you have committed and pushed all required files before you bootstrap the GitOps deployment. Otherwise, you’ll end up deploying different states from your local version while the controller will apply the Git version.
To bootstrap the GitOps deployment project, simply perform a kluctl deploy:
$ cd gitops-deployment
$ kluctl deploy -a cluster_name=test.example.com
This will deploy the GitOps deployment to the current context cluster. After this deployment, the kluctl-controller will
immediately start reconciling all deployed KluctlDeployment resources, including the one for the GitOps deployment
itself.
This means, to change any of the deployments, perform the changes in Git via your already established processes (e.g., pull-requests or direct pushes to the main branch).
GitOps commands
Each individual KluctlDeployment can be controlled and inspected via the
Kluctl CLI (check the kluctl gitops xxx sub-commands). Each command takes the
KluctlDeployment name and its namespace as arguments.
In addition, if --name and --namespace are omitted, the CLI will try to auto-detect the KluctlDeployment if your
current directory is inside a Kluctl deployment project. It does so by using the URL of the Git origin remote and the
subdirectory inside the Git repository to find one or more KluctlDeployment that refers to this project.
Suspend and resume
The CLI can suspend and resume individual KluctlDeployments. This is useful if you need to perform work that would
otherwise be hard to perform with constant reconciliation being active. This includes refactorings, migrations and other
more complex tasks. While suspended, manual reconciliation via the CLI and the Webui is still
possible.
To suspend the app1 deployment, run the following CLI command:
$ kluctl gitops suspend --namespace kluctl-gitops --name app1
While suspended, you can perform whatever actions you need without the kluctl-controller intervening. Then, to resume
the deployment, run:
$ kluctl gitops resume --namespace kluctl-gitops --name app1
Manual reconciliation
You can trigger different manual requests via the CLI. Please note that these requests are executed by the controller even though the usage of the CLI feels like things are executed locally.
Every manual request command is able to override many of the spec fields found in the KluctlDeployment. The CLI
tries its best to mimic the interface already found in the non-GitOps based commands (e.g. kluctl deploy).
As an example, with kluctl gitops deploy --namespace=xxx --name=yyy you can pass deployment arguments
via -a my_arg=my_value the same way as you can already do with kluctl deploy.
kluctl gitops diff ... before running any potentially disruptive commands. This behavior might change
in the future.The CLI will also try to detect if the Git repository in which you’re currently in is related to the Git repository used
in the referenced KluctlDeployment. In that case, the CLI will upload the local source code to the controller for a
one-time override. This means, that the kluctl-controller will actually work with your local version of the project.
This is mostly useful when you want to verify that changes are valid before actually pushing/merging your changes.
The following invocation will request a single reconciliation iteration. This means, it will do the same as described in The reconciliation loop.
$ kluctl gitops reconcile --namespace kluctl-gitops --name app1
The following invocation will perform a diff and print the result. This is especially useful if your local version of the source code contains modifications which you’d like to verify.
$ kluctl gitops diff --namespace kluctl-gitops --name app1
The following invocation will cause a manual prune (delete orphan objects).
$ kluctl gitops prune --namespace kluctl-gitops --name app1
Viewing controller logs
The following CLI command can be used to view controller logs related to a given KluctlDeployment:
$ kluctl gitops logs --namespace kluctl-gitops --name app1 -f
Using the Webui
In addition to the Kluctl GitOps commands, the Kluctl Webui can be used to monitor and
control the KluctlDeployments.
The Webui is still very experimental, meaning that many features are still missing. But generally, performing manual requests, viewing state, diffs and logs should already work good enough as of now.
Mixing
Kluctl allows you to mix pull-based GitOps with push-based CLI workflows. You can use GitOps for some targets/environments (e.g. prod) and revert to using push-based CLI workflows in other targets/environments (e.g. dev environments). This is useful if you want the security and stability of GitOps on prod while still having the flexibility and speed of development on non-prod environments.
You can also use GitOps for a target/environment to perform the actuall deployments while using kluctl diff in the
push fashion to test/verify changes before actually pushing/merging the main branch.
5 - Tutorials
5.1 - Microservices Demo
5.1.1 - 1. Basic Project Setup
Introduction
This is the first tutorial in a series of tutorials around the GCP Microservices Demo and the use of kluctl to deploy and manage the demo.
We will start with a simple kluctl project setup (this tutorial) and then advance to a multi-environment and multi-cluster setup (upcoming tutorial). Afterwards, we will also show how daily business (updates, house keeping, …) with such a deployment would look like.
GCP Microservices Demo
From the README.md of GCP Microservices Demo:
Online Boutique is a cloud-native microservices demo application. Online Boutique consists of a 10-tier microservices application. The application is a web-based e-commerce app where users can browse items, add them to the cart, and purchase them.
This demo application seems to be a good example for a more or less typical application seen on Kubernetes. It has multiple self-developed microservices while also requiring third-party applications/services (e.g. redis) to be deployed and configured properly.
Ways to deploy the demo
The simplest and most naive way to deploy the demo is by using kubectl apply with the provided release manifests:
$ kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/microservices-demo/main/release/kubernetes-manifests.yaml
This is also what is shown in the README.md of the microservices demo.
The shortcomings of this approach are however easy to spot, and probably no one would ever follow this approach up to production. As an example, updates to the application and its dependencies will be hard to maintain. Housekeeping (deleting orphan resources) will also be hard to achieve. At some point in time, when you start deploying the application multiple times to different clusters and/or different environments, configuration will also become hard to maintain, as every target might need different configuration. Long story short…without proper tooling, you’ll easily run into painful limitations.
There are multiple solutions available that each solve parts of the limitations and problems. As an example, Helm and Kustomize are well known. Introducing these tools will easily bring you much further, but you will very likely end up with something complicated/complex around these tools to make it usable in daily business. In the worst case, you’d start using Bash scripts that orchestrate your deployments.
GitOps oriented solutions like ArgoCD and Flux are able to relieve you from parts of the deployment orchestration tasks, but bring in new complexities that need to be solved as well.
Deploying with kluctl
In this tutorial, we’ll show how the microservices demo can be deployed and managed with kluctl. We will start with a simple and naive deployment to a local kind cluster. The next tutorial in this series will then focus on making the deployment multi-environment and multi-cluster capable.
The goal is to make a deployment as simple as typing:
$ kluctl deploy -t local
Setting up the kluctl project
The first thing you need is an empty project directory and the .kluctl.yml project configuration:
$ mkdir -p microservices-demo/1-basic-setup
$ cd microservices-demo/1-basic-setup
Inside this new directory, create the file .kluctl.yml with the following content:
targets:
- name: local
context: kind-kind
This is a very simple example with only a single target, being a local kind cluster.
You might have noticed that the target configuration refers a kubectl context that is not existing yet. It’s time to create a local kind cluster now. To do so, first ensure that you have kind installed and then run:
$ kind create cluster
After this, you should have a local cluster setup and your kubeconfig prepared with a new context named kind-kind.
Setting up a minimal deployment project
Inside the kluctl project, you will now have to create a minimal deployment project.
The deployment project starts with the root deployment.yml.
The location of this deployment.yml is the same as the .kluctl.yml. Create the file with following content:
deployments:
- path: redis
commonLabels:
examples.kluctl.io/deployment-project: "microservices-demo"
This minimal deployment project contains two elements:
- The list of deployment items, which currently only consists of the upcoming redis deployment. The next chapter will explain this deployment.
- The commonLabels, which is a map of common labels and values. These labels are applied to all deployed resources and are later used by kluctl to identify resources that belong to this kluctl deployment.
Setting up the redis deployment
As seen in the previous chapter, the root deployment.yml refers to a redis deployment item. This deployment item must
be located inside the sub-folder redis (hence the path: redis). kluctl expects each deployment item to be a
kustomize deployment. Such a kustomize deployment can be as simple as a kustomization.yml with
a single resources entry or a fully fledged kustomize deployment with overlays, generators, and so on.
For our example, first create the sub-directory redis:
$ mkdir redis
Then create the file redis/kustomization.yml with the following content:
resources:
- deployment.yml
- service.yml
Then create the file redis/deployment.yml with the following content:
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cart
spec:
selector:
matchLabels:
app: redis-cart
template:
metadata:
labels:
app: redis-cart
spec:
containers:
- name: redis
image: redis:alpine
ports:
- containerPort: 6379
readinessProbe:
periodSeconds: 5
tcpSocket:
port: 6379
livenessProbe:
periodSeconds: 5
tcpSocket:
port: 6379
volumeMounts:
- mountPath: /data
name: redis-data
resources:
limits:
memory: 256Mi
cpu: 125m
requests:
cpu: 70m
memory: 200Mi
volumes:
- name: redis-data
emptyDir: {}
And the file redis/service.yml:
apiVersion: v1
kind: Service
metadata:
name: redis-cart
spec:
type: ClusterIP
selector:
app: redis-cart
ports:
- name: redis
port: 6379
targetPort: 6379
The above files (deployment.yml and service.yml) are based on the content of redis.yaml
from the original GCP Microservices Demo.
As you can see, there is nothing special about the contents of these files so far. It’s simple and plain Kubernetes and YAML resources. The full potential of kluctl will become clear later, when we start to use templating inside these files. Only with the templating, it will become possible to support multi-environment and multi-cluster deployments.
Setting up the first microservice
Now it’s time to setup the first microservice. It is done the same way as we’re already setup the redis deployment.
First, create the sub-directory cartservice at the same level as you created the redis sub-directory. Then create
the following files.
Another kustomization.yml
resources:
- deployment.yml
- service.yml
Another deployment.yml, with the content found here
Another service.yml, with the content found here
Finally add the new deployment item to the root deployment.yml
...
deployments:
...
# add this line
- path: cartservice
...
Setting up all other microservices
The GCP Microservices Demo is composed of multiple other services, which can be setup the same way as the microservice shown before. You can do this by yourself, or alternatively switch to the completed example found here.
From now on, we will assume that all microservices have been added (or that you switched to the example project).
Deploy it!
We now have a minimal kluctl project with two simple kustomize deployments. It’s time to deploy it. From inside the kluct project directory, call:
$ kluctl deploy -t local
INFO[0000] Rendering templates and Helm charts
INFO[0000] Building kustomize objects
Do you really want to deploy to the context/cluster kind-kind? (y/N) y
INFO[0001] Getting remote objects by commonLabels
INFO[0001] Getting 24 additional remote objects
INFO[0001] Running server-side apply for all objects
INFO[0001] shippingservice: Applying 2 objects
INFO[0001] paymentservice: Applying 2 objects
INFO[0001] currencyservice: Applying 2 objects
INFO[0001] frontend: Applying 3 objects
INFO[0001] loadgenerator: Applying 1 objects
INFO[0001] recommendationservice: Applying 2 objects
INFO[0001] productcatalogservice: Applying 2 objects
INFO[0001] adservice: Applying 2 objects
INFO[0001] cartservice: Applying 2 objects
INFO[0001] emailservice: Applying 2 objects
INFO[0001] checkoutservice: Applying 2 objects
INFO[0001] redis: Applying 2 objects
New objects:
default/Deployment/adservice
default/Deployment/cartservice
default/Deployment/checkoutservice
default/Deployment/currencyservice
default/Deployment/emailservice
default/Deployment/frontend
default/Deployment/loadgenerator
default/Deployment/paymentservice
default/Deployment/productcatalogservice
default/Deployment/recommendationservice
default/Deployment/redis-cart
default/Deployment/shippingservice
default/Service/adservice
default/Service/cartservice
default/Service/checkoutservice
default/Service/currencyservice
default/Service/emailservice
default/Service/frontend
default/Service/frontend-external
default/Service/paymentservice
default/Service/productcatalogservice
default/Service/recommendationservice
default/Service/redis-cart
default/Service/shippingservice
The -t local selects the local target which was previously defined in the .kluctl.yml. Right now we only have this
one target, but we will add more targets in upcoming tutorials from this series.
Answer with y to the question if you really want to deploy. The command will output what is happening and then show
what has been changed on the target.
Playing around
You have now deployed redis and the cartservice microservice. You can now start to play around with some other kluctl
commands. For example, try to change something inside cartservice.yml (e.g. set terminationGracePeriodSeconds to 10)
and then run kluctl diff -t local:
$ kluctl diff -t local
INFO[0000] Rendering templates and Helm charts
...
Changed objects:
default/Deployment/cartservice
Diff for object default/Deployment/cartservice
+--------------------------------------------------+---------------------------+
| Path | Diff |
+--------------------------------------------------+---------------------------+
| spec.template.spec.terminationGracePeriodSeconds | -5 |
| | +10 |
+--------------------------------------------------+---------------------------+
As you can see, kluctl now shows you what will happen. If you’d now perform a kluctl deploy -t local, kluctl would
output what has happened (which would be the same as in the diff as long as you don’t change anything else).
If you try to remove (or at least comment out) a microservice, e.g. the cartservice and then run
kluctl diff -t local again, you will get:
$ kluctl diff -t local
INFO[0000] Rendering templates and Helm charts
...
Changed objects:
default/Deployment/cartservice
Diff for object default/Deployment/cartservice
+--------------------------------------------------+---------------------------+
| Path | Diff |
+--------------------------------------------------+---------------------------+
| spec.template.spec.terminationGracePeriodSeconds | -5 |
| | +10 |
+--------------------------------------------------+---------------------------+
Orphan objects:
default/Service/cartservice
default/Deployment/cartservice
As you can see, the resources belonging cartservice are listed as “Orphan objects” now, meaning that these are not found locally anymore.
A kluctl prune -t local would then give:
$ kluctl prune -t local
INFO[0000] Rendering templates and Helm charts
...
Do you really want to delete 2 objects? (y/N) y
Deleted objects:
default/Service/cartservice
default/Deployment/cartservice
How to continue
The result of this tutorial is a naive version of the microservices demo deployment. There are a few things that you would solve differently in the real world, e.g. use Helm Charts for things like redis instead of proving self-crafted manifests. The next tutorials in this series will focus on a few improvements and refactorings that will make this kluctl project more “realistic” and more useful. They will also introduce concepts like multi-environment and multi-cluster deployments.
5.1.2 - 2. Helm Integration
Introduction
The first tutorial in this series demonstrated how to setup a simple kluctl project that is able to deploy the GCP Microservices Demo to a local kind cluster.
This initial kluctl project was however quite naive and too simple to be any way realistic. For example, the project structure is too flat and will likely result in chaos when the project grows. Also, the project used self-crafted manifests while it might have been better to reuse feature rich Helm Charts. We will fix both these issues in this tutorial.
How to start
This tutorial is based on the results of the first tutorial. As an alternative, you can take the 1-basic-project
example project found here
and use it the base to be able to continue with this tutorial.
You can also deploy the base project and then incrementally perform deployments after each step in this tutorial. This way you will also gain some experience and feeling for to use kluctl.
A simple refactoring
Let’s start with a simple refactoring. Having all deployment items on the root level will easily get unmaintainable.
kluctl allows you to structure your project in all kinds of fashions by leveraging sub-deployments. The
deployment items found in deployment projects
allows specifying includes which point to sub-directory
with another deployment.yml.
Let’s split the deployment into third-party applications (currently only redis) and the project specific microservices.
To do this, create the sub-directories third-party and microservices. Then move the redis directory into third-party
and all microservice sub-directories into microservices:
$ mkdir third-party
$ mkdir microservices
$ mv redis third-party/
$ mv adservice cartservice checkoutservice currencyservice emailservice \
frontend loadgenerator paymentservice \
productcatalogservice recommendationservice shippingservice microservices/
Now change the deployments list inside the root deployment.yml to:
deployments:
- include: third-party
- include: services
Add a deployment.yml with the following content into the third-party sub-directory:
deployments:
- path: redis
And finally a deployment.yml with the following content into the microservices sub-directory:
deployments:
- path: adservice
- path: cartservice
- path: checkoutservice
- path: currencyservice
- path: emailservice
- path: frontend
- path: loadgenerator
- path: paymentservice
- path: productcatalogservice
- path: recommendationservice
- path: shippingservice
To get an overview of these changes, look into this commit inside the example project belonging to this tutorial.
If you deploy the new state of the project, you’ll notice that only labels will change. These labels are automatically added to all resources and represent the tags of the corresponding deployment items.
Some notes on project structure
The refactoring from above is meant as an example that demonstrates how sub-deployments can be used to structure your project. Such sub-deployments can also include deeper sub-deployments, allowing you to structure your project in any way and complexity that fits your needs.
Introducing the first Helm Chart
There are many examples where self-crafting of Kubernetes manifests is not the best solution, simply because there is already a large ecosystem of pre-created Kubernetes packages in the form of Helm Charts.
The redis deployment found in the microservices demo is a good example for this, especially as many available Helm Charts offer quite some functionality, for example high availability.
kluctl allows the integration of Helm Charts, which we will do now to replace the self-crafted redis deployment with the Bitname Redis Chart.
First, create the file third-party/redis/helm-chart.yml with the following content:
helmChart:
repo: https://charts.bitnami.com/bitnami
chartName: redis
chartVersion: 16.8.0
releaseName: cart
namespace: default
output: deploy.yml
Most of the above configuration can directly be mapped to Helm invocations (pull, install, …). The output
value has a special meaning and must be reflected inside the kustomization.yml resources list. The reason is that
kluctl solves the Helm integration by running helm template and writing
the result to the file configured via output. After this, kluctl expects that kustomize takes over, which requires
that the generated file is references in kustomization.yml.
To do so, simply replace the content of third-party/redis/kustomization.yml with:
resources:
- deploy.yml
We now need some configuration for the redis chart, which is provides via [third-party/redis/helm-values.yml`](https://kluctl.io/docs/kluctl/deployments/helm/#helm-valuesyml):
architecture: replication
auth:
enable: false
sentinel:
enabled: true
quorum: 2
replica:
replicaCount: 3
persistence:
enabled: true
master:
persistence:
enabled: true
The above configuration will configure redis to run in replication mode with sentinel and 3 replicas, giving us some high availability (at least in theory, as we’d still need a HA Kubernetes cluster and proper affinity configuration).
The Redis Chart will also deploy a Service resource, but with a different name as the self-crafted version. This means
we have to fix the service name in microservices/cartservice/deployment.yml (look for the environment variable REDIS_ADDR)
to point to cart-redis:6379 instead of redis-cart:6379.
You can now remove the old redis related manifests (third-party/redis/deployment.yml and third-party/redis/service.yml).
All the above changes can be found in this commit from the example project.
Pulling Helm Charts
We have now added a Helm Chart to our deployment, but to make it deployable it must be pre-pulled first. kluctl requires Helm Charts to be pre-pulled for multiple reasons. The most important reasons are performance and reproducibility. Performance would significantly suffer if Helm Chart would have to be pulled on-demand at deployment time. Also, Helm Charts have no functionality to ensure that a chart that you pulled yesterday is equivalent to the chart pulled today, even if the version is unchanged.
To pre-pull the redis Helm Chart, simply call:
$ kluctl helm-pull
INFO[0000] Pulling for third-party/redis/helm-chart.yml
This will pre-pull the chart into the sub-directory third-party/redis/charts. This directory is meant to be added
to version control, so that it is always available when deploying.
If you ever change the chart version in helm-chart.yml, don’t forget to re-run the above command and commit the
resulting changes.
Deploying the current state
It’s time to deploy the current state again:
$ kluctl deploy -t local
INFO[0000] Rendering templates and Helm charts
...
New objects:
default/ConfigMap/cart-redis-configuration
default/ConfigMap/cart-redis-health
default/ConfigMap/cart-redis-scripts
default/Service/cart-redis
default/Service/cart-redis-headless
default/ServiceAccount/cart-redis
default/StatefulSet/cart-redis-node
Changed objects:
default/Deployment/cartservice
Diff for object default/Deployment/cartservice
+-------------------------------------------------------+------------------------------+
| Path | Diff |
+-------------------------------------------------------+------------------------------+
| spec.template.spec.containers[0].env.REDIS_ADDR.value | -redis-cart:6379 |
| | +cart-redis:6379 |
+-------------------------------------------------------+------------------------------+
Orphan objects:
default/Deployment/redis-cart
default/Service/redis-cart
As you can see, the changes that we did to the kluctl project are reflected in the output of the deploy call, meaning that we can perfectly see what happened. We can see a few new resources which are all redis related, the change of the service name and the old redis resources being marked as orphan. Let’s get rid of the orphan resources:
$ kluctl prune -t local
INFO[0000] Rendering templates and Helm charts
INFO[0000] Building kustomize objects
INFO[0000] Getting remote objects by commonLabels
The following objects will be deleted:
default/Service/redis-cart
default/Deployment/redis-cart
Do you really want to delete 2 objects? (y/N) y
Deleted objects:
default/Service/redis-cart
default/Deployment/redis-cart
You have just performed your first house-keeping, which you’ll probably do quite often from now on in your daily DevOps business.
More house-keeping
When time passes, new versions of the Helm Charts that you integrated are going to be released. You might have to keep
your deployments up-to-date in such cases. The most naive way is to simply increase the chart version inside helm-chart.yml
and then simply re-call kluctl helm-pull.
As the number of used charts can easily grow to a number where it becomes hard to keep everything up-to-date, kluctl offers a command to support you in this:
$ kluctl helm-update
INFO[0005] Chart third-party/redis/helm-chart.yml has new version 16.8.2 available. Old version is 16.8.0.
As you can see, it will display charts with new versions. You can also use the same command to actually update the
helm-chart.yml files and ultimately commit these to git:
$ kluctl helm-update --upgrade --commit
INFO[0005] Chart third-party/redis/helm-chart.yml has new version 16.8.2 available. Old version is 16.8.0.
INFO[0005] Pulling for third-party/redis/helm-chart.yml
INFO[0010] Committing: Updated helm chart third-party/redis from 16.8.0 to 16.8.2
How to continue
After this tutorial, you have hopefully learned how to better structure your projects and how to integrate third-party Helm Charts into your project, including some basic house-keeping tasks.
The next tutorials in this series will show you how to use this kluctl project as a base to implement a multi-environment and multi-cluster deployment.
5.1.3 - 3. Templating and multi-env deployments
Introduction
The second tutorial in this series demonstrated how to integrate Helm into your deployment project and how to keep things structured.
The project is however still not flexible enough to be deployed multiple times and/or in different flavors. As an example, it doesn’t make much sense to deploy redis with replication on a local cluster, as there can’t be any high availability with single node. Also, the resource requests currently used are quite demanding for a single node cluster.
How to start
This tutorial is based on the results of the second tutorial. As an alternative, you can take the 2-helm-integration
example project found here
and use it as the base to be able to continue with this tutorial.
This time, you should start with a fresh kind cluster. If you are sure that you won’t loose any critical data by deleting the existing cluster, simply run:
$ kind delete cluster
$ kind create cluster
If you’re unsure or if you want to re-use the existing cluster for some reason, you can also simply delete the old deployment:
$ kluctl delete -t local
INFO[0000] Rendering templates and Helm charts
INFO[0000] Building kustomize objects
INFO[0000] Getting remote objects by commonLabels
The following objects will be deleted:
default/Service/emailservice
...
default/ConfigMap/cart-redis-scripts
Do you really want to delete 29 objects? (y/N) y
Deleted objects:
default/ConfigMap/cart-redis-scripts
...
default/StatefulSet/cart-redis-node
The reason to start with a fresh deployment is that we will later switch to different namespaces and stop using the
default namespace.
Targets
If we want to allow the deployment to be deployed multiple times, we first need multiple targets in our project. Let’s
add 2 targets called test and prod. To do so, modify the
content of .kluctl.yml to contain:
targets:
- name: local
context: kind-kind
args:
env_type: local
- name: test
context: kind-kind
args:
env_type: real
- name: prod
context: kind-kind
args:
env_type: real
You might notice that all targets point to the kind cluster at the moment. This is of course not how you would do it in a real project as you’d probably have at least one real production-ready cluster to target your deployments against.
We’ve also introduced args for each target, with each target
having an env_type argument configured. This argument will later be used to change details of the deployment, depending
on the value of it. For example, setting it to local might change the redis deployment into a single-node/standalone
deployment.
Dynamic namespaces
One of the most obvious and also useful application of templates is making namespaces dynamic, depending on the target that you want to deploy. This allows to deploy the same set of deployment/manifests multiple times, even to the same cluster.
There are a few predefined variables which are always available
in all deployments. One of these variables is the target dictionary which is a copy of the currently processed target.
This means, we can use {{ target.name }} to insert the current target name through templating.
There are multiple ways to change the namespaces of involved resources. The most naive way is to go directly into the
manifests and add the metadata.namespace field. For example, you could edit services/adservice/deployment.yml this
way:
apiVersion: apps/v1
kind: Deployment
metadata:
name: adservice
namespace: ms-demo-{{ target.name }}
...
This can however easily lead to resources being missed or resources where you are not in control, e.g. rendered
Helm Charts. Another way to set the namespace on multiple resources is by using the
namespace property of kustomize.
For example, instead of changing the adservice deployment directly, you could modify the content of
services/adservice/kustomization.yml to:
resources:
- deployment.yml
- service.yml
namespace: ms-demo-{{ target.name }}
This is better than the naive solution, but still limited in a comparable (but not as bad) way. The most powerful and
preferred solution is use overrideNamespace
in the root deployment.yml:
...
overrideNamespace: ms-demo-{{ target.name }}
...
As an alternative, you could also use overrideNamespace separately in third-party/deployment.yml and
services/deployment.yml. In this case, you’re also free to use different prefixes for the namespaces, as long as you
include {{ target.name }} in them.
overrideNamespace only takes effect on a kustomize deployment if it does NOT specify namespace.
If you followed the kustomization.yml example from above, make sure to undo the changes to kustomization.yml.Helm Charts and namespaces
The previously described way of making namespaces dynamic in all resources works well for most cases. There are however
situations where this is not enough, mostly when the name of the namespace is used in other places than metadata.namespace.
Helm Charts very often do this internally, which makes it necessary to also include the dynamic namespace into the
helm-chart.yml’s namespace property. You will have to do this for the redis chart as well, so let’s modify
third-party/redis/helm-chart.yml to:
helmChart:
repo: https://charts.bitnami.com/bitnami
chartName: redis
chartVersion: 16.8.2
releaseName: cart
namespace: ms-demo-{{ target.name }}
output: deploy.yml
Without this change, redis is going to be deployed successfully but will then fail to start due to wrong internal references to the default namespace.
Making commonLabels unique per target
commonLabels in your root deployment.yml has
a very special meaning which is important to understand and work with. The combination of all commonLabels MUST be unique
between all supported targets on a cluster, including the ones that don’t exist yet and are from other kluctl projects.
This is because kluctl uses these to identify resources belonging to the currently processed deployment/target, which becomes especially important when deleting or pruning.
To fulfill this requirement, change the root deployment.yml to:
...
commonLabels:
examples.kluctl.io/deployment-project: "microservices-demo"
examples.kluctl.io/deployment-target: "{{ target.name }}"
...
examples.kluctl.io/deployment-project ensures that we don’t get in conflict with any other kluctl project that might
get deployed to the same cluster. examples.kluctl.io/deployment-target ensures that the same deployment can be deployed
once per target. The names of the labels are arbitrary, and you can choose whatever you like.
Creating necessary namespaces
If you’d try to deploy the current state of the project, you’d notice that it will result in many errors where kluctl
says that the desired namespace is not found. This is because kluctl does not create namespaces on its own. It also
does not do this for Helm Charts, even if helm install for the same charts would do this. In kluctl you have to
create namespaces by yourself, which ensures that you have full control over them.
This implies that we must create the necessary namespace resource by ourselves. Let’s put it into its own kustomize deployment below
the root directory. First, create the namespaces directory and place a simple kustomization.yml into it:
resources:
- namespace.yml
In the same directory, create the manifest namespace.yml:
apiVersion: v1
kind: Namespace
metadata:
name: ms-demo-{{ target.name }}
Now add the new kustomize deployment to the root deployment.yml:
deployments:
- path: namespaces
- include: third-party
- include: services
...
Deploying multiple targets
You’re now able to deploy the current deployment multiple times to the same kind cluster. Simply run:
$ kluctl deploy -t local
$ kluctl deploy -t prod
After this, you’ll have two namespaces with the same set of microservices and two instances of redis (both replicated with 3 replicas) deployed.
All changes together
For a complete overview of the necessary changes to get to this point, look into this commit.
Make the local target more lightweight
Having the microservices demo deployed twice might easily lead to you local cluster being completely overloaded. The solution would obviously be to not deploy the prod target to your local cluster and instead use a real cluster.
However, for the sake of this tutorial, we’ll instead try to introduce a few differences between targets so that they fit better onto the local cluster.
To do so, let’s introduce variables files that contain different sets of configuration for different environment types. These variables files are simply yaml files with arbitrary content, which is then available in future templating contexts.
First, create the sub-directory vars in the root project directory. The name of this directory is arbitrary and up to
you, it must however match what is later used in the deployment.yml.
Inside this directory, create the file local.yml with the following content:
redis:
architecture: standalone
# the standalone architecture exposes redis via a different service then the replication architecture (which uses sentinel)
svcName: cart-redis-master
And the file real.yml with the following content:
redis:
architecture: replication
# the standalone architecture exposes redis via a different service then the replication architecture (which uses sentinel)
svcName: cart-redis
To load these variables files into the templating context, modify the root deployment.yml and add the following to the top:
vars:
- file: ./vars/{{ args.env_type }}.yml
...
As you can see, we can even use templating inside the deployment.yml. Generally, templating can be used everywhere,
with a few limitations outlined in the documentation.
The above changes will now load a different variables file, depending on which env_type was specified in the currently
processed target. This allows us to customize all kinds of configurations via templating. You’re completely free in how
you use this feature, including loading multiple variables files where each one can use the variables loaded by the
previous variables file.
To use the newly introduces variables, first modify the content of third-party/redis/helm-values.yml to:
architecture: {{ redis.architecture }}
auth:
enabled: false
{% if redis.architecture == "replication" %}
sentinel:
enabled: true
quorum: 2
replica:
replicaCount: 3
persistence:
enabled: true
{% endif %}
master:
persistence:
enabled: true
The templating engine used by kluctl is currently Jinja2. We suggest reading through the documentation of Jinja2 to understand what is possible. In the example above, we use simple variable expressions and if/else statements.
We will also have to replace the occurrence of cart-redis:6379 with {{ redis.svcName }}:6379 inside
services/cartservice/deployment.yml.
For an overview of the above changes, look into this commit.
Deploying the current state
You can now try to deploy the local and test targets. You’ll notice that the local deployment will result in quite
a few changes (seen in the diff) and the test target not having any changes at all. You might also want to do a prune
for the local target to get rid of the old redis deployment.
Disable a few services for local
Some services are not needed locally or might not even be able to run properly. Let’s assume this applies to the services
loadgenerator and emailservice. We can conditionally remove these from the deployment with simple boolean variables
in vars/local.yml and vars/real.yml and if/else statements in services/deployment.yml.
Add the following variables to vars/local.yml:
...
services:
emailservice:
enabled: false
loadgenerator:
enabled: false
And the following variables to vars/real.yml:
...
services:
emailservice:
enabled: true
loadgenerator:
enabled: true
Now change the content of services/deployment.yml to:
deployments:
- path: adservice
- path: cartservice
- path: checkoutservice
- path: currencyservice
{% if services.emailservice.enabled %}
- path: emailservice
{% endif %}
- path: frontend
{% if services.loadgenerator.enabled %}
- path: loadgenerator
{% endif %}
- path: paymentservice
- path: productcatalogservice
- path: recommendationservice
- path: shippingservice
A deployment to test should not change anything now. Deploying to local however should reveal multiple orphan resources,
which you can then prune.
For an overview of the above changes, look into this commit.
How to continue
After this tutorial, you should have a basic understanding how templating in kluctl works and how a multi-environment deployment can be implemented.
We however only deployed to a single cluster so far and are unable to properly manage the image versions of our microservices at the moment. In the next tutorial of this series, we’ll learn how to deploy to multiple clusters and split third-party image management and (self developed) application image management.
6 - Examples
6.1 - Simple
Description
This example is a very simple one that shows how to define a target cluster, context, create a
namespace and deploy a nginx. You can configure the name of the namespace by changing the arg environment in
.kluctl.yml.
Prerequisites
- A running kind cluster with a context named
kind-kind. - Of course, you need to install kluctl. Please take a look at the installation guide, in case you need further information.
How to deploy
git clone git@github.com:kluctl/kluctl-examples.git
cd kluctl-examples/simple
kluctl diff --target simple
kluctl deploy --target simple
6.2 - Simple Helm
Description
This example is very similar to simple but it deploys a Helm-based nginx to
give a first impression how kluctl and Helm work together.
Prerequisites
- A running kind cluster with a context named
kind-kind. - Of course, you need to install kluctl. Please take a look at the installation guide, if you need further information.
- You also need to install Helm. Please take a look at the Helm installation guide for further information.
How to deploy
git clone git@github.com:kluctl/kluctl-examples.git
cd kluctl-examples/simple-helm
kluctl helm-pull
kluctl diff --target simple-helm
kluctl deploy --target simple-helm
6.3 - Microservices demo
Description
This example is a more complex one and contains the files for the microservices tutorial inspired by the Google Online Boutique Demo.
Prerequisites
Please take a look at Tutorials for prerequisites.
How to deploy
Please take a look at Tutorials for deployment instructions.
7 - Template Controller
The Template Controller is a controller originating from the Kluctl project, but not limited to Kluctl. It allows to define template objects which are rendered and applied into the cluster based on an input matrix.
In its easiest form, an ObjectTemplate takes one input object (e.g. a ConfigMap) and creates another object
(e.g. a Secret) which is then applied into the cluster.
The Template Controller also offers CRDs which allow to query external resources (e.g. GitHub Pull Requests) which can
then be used as inputs into ObjectTemplates.
Use Cases
Template Controller has many use case. Some are for example:
Documentation
Reference documentation is available here.
The announcement blog post also contains valuable explanations and examples.
Installation
Installation instructions can be found here
7.1 - Installation
The Template Controller can currently be installed via static manifests or via Helm.
Static Manifests
kubectl apply -f "https://raw.githubusercontent.com/kluctl/template-controller/v0.9.4/deploy/manifests/template-controller.yaml"
Helm
A Helm Chart for the controller is available as well. To install the controller via Helm, run:
$ helm install template-controller -n template-controller --create-namespace oci://ghcr.io/kluctl/charts/template-controller
The Helm Chart is only distributed as an OCI package. The old Helm Repository found at https://github.com/kluctl/charts is not maintained anymore.
Upgrading from older Helm Charts
In case you were using the Helm Chart found at https://github.com/kluctl/charts, you’ll need to perform a few extra steps before you can upgrade to the new OCI based Helm Charts.
Run the following commands while the correct Kubectl Context is set. Please replace <release-name> with the release
name and <release-namespace> with the namespace you used when installing the old Chart.
$ rn=<release-name>
$ ns=<release-namespace>
$ for i in $(kubectl get crd -oname | grep templates.kluctl.io); do kubectl label $i app.kubernetes.io/managed-by=Helm; done
$ for i in $(kubectl get crd -oname | grep templates.kluctl.io); do kubectl annotate $i meta.helm.sh/release-name=$rn; done
$ for i in $(kubectl get crd -oname | grep templates.kluctl.io); do kubectl annotate $i meta.helm.sh/release-namespace=$ns; done
After this, you can perform a normal upgrade using the new OCI Chart.
$ helm upgrade -n <release-namespace> <release-name> oci://ghcr.io/kluctl/charts/template-controller
7.2 - Specs
7.2.1 - v1alpha1 specs
templates.kluctl.io/v1alpha1
This is the v1alpha1 API specification for defining templating related resources.
Specification
- ObjectTemplate CRD
- TextTemplate CRD
- GitProjector CRD
- ListGithubPullRequests CRD
- ListGitlabMergeRequests CRD
- GithubComment CRD
- GitlabComment CRD
Implementation
7.2.1.1 - ObjectTemplate
The ObjectTemplate API defines templates that are rendered based on a matrix of input values.
Example
apiVersion: v1
kind: ConfigMap
metadata:
name: input-configmap
namespace: default
data:
x: someValue
---
apiVersion: templates.kluctl.io/v1alpha1
kind: ObjectTemplate
metadata:
name: example-template
namespace: default
spec:
serviceAccountName: example-template-service-account
prune: true
matrix:
- name: input1
object:
ref:
apiVersion: v1
kind: ConfigMap
name: input-configmap
templates:
- object:
apiVersion: v1
kind: ConfigMap
metadata:
name: "templated-configmap"
data:
y: "{{ matrix.input1.x }}"
- raw: |
apiVersion: v1
kind: ConfigMap
metadata:
name: "templated-configmap-from-raw"
data:
z: "{{ matrix.input1.x }}"
The above manifests show a simple example that will create two ConfigMaps from one input ConfigMap. The individual fields
possible in ObjectTemplate are described further down.
Spec fields
The following fields are supported in spec.
serviceAccountName
ObjectTemplate requires a service account to access cluster objects. This is required when it gathers input objects
for the matrix and when it applies rendered objects. Please see security for some important notes!
For this to work, the referenced service account must have at least GET, CREATE and UPDATE permissions for
the involved objects and kinds. For the above example, the following service account would be enough:
apiVersion: v1
kind: ServiceAccount
metadata:
name: example-template-service-account
namespace: default
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: example-template-service-account
namespace: default
rules:
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["*"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: example-template-service-account
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: example-template-service-account
subjects:
- kind: ServiceAccount
name: example-template-service-account
namespace: default
interval
Specifies the interval at which the ObjectTemplate is reconciled.
suspend
If set to true, reconciliation is suspended.
prune
If true, the Template Controller will delete rendered objects when either the ObjectTemplate gets deleted or when
the rendered object disappears from the rendered objects list.
matrix
The matrix defines a list of matrix entries, which are then used as inputs into the templates. Each entry results in
a list of values associated with the entry name. All lists are then multiplied together to form the actual matrix of
input values.
Each matrix entry has a name, which is later used to identify the value in the template.
As an example, if you have two entries with simple lists with the following values:
matrix:
- name: input1
list:
- a: v1
b: v2
- name: input2
list:
- c: v3
d: v4
It will lead to the following matrix:
- input1:
a: v1
b: v2
input2:
c: v3
d: v4
Now take the following matrix example with an entry with two list items:
matrix:
- name: input1
list:
- a: v1
b: v2
- a: v1_2
b: v2_2
- name: input2
list:
- c: v3
d: v4
It will lead to the following matrix:
- input1:
a: v1
b: v2
input2:
c: v3
d: v4
- input1:
a: v1_2
b: v2_2
input2:
c: v3
d: v4
Each input value is then used as input when rendering the templates. In the above examples, it means that all templates
are rendered twice, once with matrix.input1 set to the first input value and the second time with the second input
value.
The following matrix entry types are supported:
list
This is the simplest form and represents a list of arbitrary objects. See the above examples.
Due to the use of controller-gen and an internal limitation in regard to validation and CRD generation, list elements must be objects at the moment. A future version of the Template Controller will support arbitrary values (e.g. numbers and strings) as elements.
object
This refers an object on the cluster. The object is read by the controller and then used as an input value for the matrix. Example:
matrix:
- name: input1
object:
ref:
apiVersion: v1
kind: ConfigMap
name: input-configmap
The referenced object can be of any kind, but the used service account must have access to the referenced object. The read object is then wholly used as matrix input.
To only use a sub-part of the referenced object, set jsonPath to a valid JSON Path
pointing to the subfield(s) that you want to use. Example:
matrix:
- name: input1
object:
ref:
apiVersion: v1
kind: ConfigMap
name: input-configmap
jsonPath: .data
This will make the data field available as input instead of the full object, meaning that values can be used inside the
templates by simply referring {{ matrix.input1.my_key }} (no .data required).
In case you want to interpret a subfield as an input list instead of a single value, set expandLists to true.
Example:
matrix:
- name: input1
object:
ref:
apiVersion: templates.kluctl.io/v1alpha1
kind: ListGithubPullRequests
name: list-gh-prs
jsonPath: status.pullRequests
expandLists: true
This will lead to one matrix input per list element at status.pullRequests instead of a single matrix input that
represents the list.
templates
templates is a list of template objects. Each template object is rendered and applied once per entry from the
multiplied matrix inputs. When rendering, the context contains the global variable matrix representing the current
entry. matrix has one member field per named matrix input.
In the lists example from above, this would for example give matrix.input1 and matrix.input2 for each render
invocation.
In case a template object is missing the namespace, it is set to the namespace of the ObjectTemplate object.
The service account used for the ObjectTemplate must have permissions to get and apply the
resulting objects.
There are currently two forms of template objects supported, object and raw. object is an inline object where
each string field is treated as independent template to render. raw represents one large (multi-line) string that
is rendered in one-go and then unmarshalled as yaml/json.
It is recommended to prefer object over raw and only revert to raw templates when you need to perform advanced
templating (e.g. {% if ... %} or other control structures) or when it is important to treat a field as non-string
(e.g. boolean or number) when unmarshalled into an object. An example for such case would be if you want to use a
template value for replicas of a Deployment, which MUST be a number.
Example for an object:
templates:
- object:
apiVersion: v1
kind: ConfigMap
metadata:
name: "templated-configmap"
data:
y: "{{ matrix.input1.x }}"
Example for a raw template object:
templates:
- raw: |
apiVersion: v1
kind: ConfigMap
metadata:
name: "templated-configmap-from-raw"
data:
z: "{{ matrix.input1.x }}"
See templating for more details on the templating engine.
7.2.1.2 - GitProjector
The GitProjector API defines projections of Git repositories.
Projection of Git repositories means that the content of selected branches and selected files are loaded into Kubernetes,
accessible through the status of the GitProjector.
The projected branches and files can then be used as matrix inputs for an ObjectTemplate.
Example
apiVersion: templates.kluctl.io/v1alpha1
kind: GitProjector
metadata:
name: preview
namespace: default
spec:
interval: 1m
url: https://github.com/kluctl/kluctl-examples.git
# In case you use a private repository
secretRef:
name: git-credentials
ref:
branch: main
files:
- glob: "preview-envs/preview-*.yaml"
parseYaml: true
The above example creates a GitProjector that will periodically clone the kluctl-examples repo, look for the main
branch and all files matching the given glob. It will then parse all yamls and make them available through the
GitProjector’s status:
apiVersion: templates.kluctl.io/v1alpha1
kind: GitProjector
metadata:
name: preview
namespace: default
spec:
...
status:
allRefsHash: 104d3dc9b5ffabf5ba3c76532fb71da58757c494acdcb7dff3665d256f516612
conditions:
- lastTransitionTime: "2022-12-14T09:09:51Z"
message: Success
observedGeneration: 1
reason: Success
status: "True"
type: Ready
result:
- files:
- parsed:
- envName: preview-env1
replicas: 3
path: preview-envs/preview-env1.yaml
- parsed:
- envName: preview-env2
replicas: 1
path: preview-envs/preview-env2.yaml
ref:
branch: main
Spec fields
The following fields are supported in spec.
interval
Specifies the interval at which the GitProjector is reconciled.
suspend
If set to true, reconciliation is suspended.
url
The git url of the repository to project. Can either be a https or a git/ssh url.
ref
The git reference to project. Either spec.ref.branch or spec.ref.tag must be set.
Both tags and refs can be regular expressions. In case of a regular expression, the controller will include all matching
refs in the status.result field.
secretRef
Same as in the Kluctl Controllers KluctlDeployment
files
List of file to project into the status. Must be of the format:
...
spec:
...
files:
- glob: "my-file.yaml"
parseYaml: true
Each entry must at least contain a glob which is used to match files. The controller uses the https://github.com/gobwas/glob
library for pattern matching.
If parseYaml is set to true, the controller will try to parse matching files as yaml and include the parsed structured
data in the resulting status. Parsing of yaml is done with the assumption that all files possibly contain multiple yaml
documents, meaning that even yaml files with just a single document will result in a parsed list of one document.
Consider the following matching yaml file:
envName: preview-env1
replicas: 3
This will result in the following projection:
...
status:
result:
- files:
- parsed:
- envName: preview-env1
replicas: 3
path: preview-envs/preview-env1.yaml
ref:
branch: main
If parseYaml is false, the result will contain a raw string representation of the matching files:
...
status:
result:
- files:
- path: preview-envs/preview-env1.yaml
raw: |-
envName: preview-env1
replicas: 3
ref:
branch: main
7.2.1.3 - GithubComment
The GithubComment API allows to post a comment to a GitHub Pull Request.
Example
apiVersion: v1
kind: ConfigMap
metadata:
name: my-configmap
namespace: default
data:
my-key: |
This can by **any** form of [Markdown](https://en.wikipedia.org/wiki/Markdown) supported by Github.
---
apiVersion: templates.kluctl.io/v1alpha1
kind: GithubComment
metadata:
name: comment-gh
namespace: default
spec:
github:
owner: my-org-or-user
repo: my-repo
pullRequestId: 1234
tokenRef:
secretName: git-credentials
key: github-token
comment:
source:
configMap:
name: my-configmap
key: my-key
The above example will post a comment to the specified pull request. The comment’s content is loaded from the ConfigMap
my-configmap. Other sources are also supported, see the source field documentation for details.
The comment will be updated whenever the underlying comment source changes.
Spec fields
suspend
If set to true, reconciliation of this comment is suspended.
github
Specifies which GitHub project and pull request to post the comment to.
github.owner
Specifies the user or organisation name where the repository is localed.
github.repo
Specifies the repository name to query PRs for.
github.tokenRef
In case of private repositories, this field can be used to specify a secret that contains a GitHub API token.
github.pullRequestId
Specifies the ID of the pull request.
comment
This field specifies the necessary information for the comment content.
comment.id
This optional field specifies the identifier to mark the comment with so that the controller can identify it. It defaults to a generated id built from the namespace and name of the comment resource.
comment.source
This specifies the comment source. Multiple source types are supported, specified via a sub-field.
comment.source.text
Raw text for the template’s content. Example:
apiVersion: templates.kluctl.io/v1alpha1
kind: GithubComment
metadata:
name: comment-gh
namespace: default
spec:
github:
owner: my-org-or-user
repo: my-repo
pullRequestId: 1234
tokenRef:
secretName: git-credentials
key: github-token
comment:
source:
text: |
This can by **any** form of [Markdown](https://en.wikipedia.org/wiki/Markdown) supported by Github.
comment.source.configMap
Uses a ConfigMap as source for the comment’s content. Example:
apiVersion: v1
kind: ConfigMap
metadata:
name: my-configmap
namespace: default
data:
my-key: |
This can by **any** form of [Markdown](https://en.wikipedia.org/wiki/Markdown) supported by Github.
---
apiVersion: templates.kluctl.io/v1alpha1
kind: GithubComment
metadata:
name: comment-gh
namespace: default
spec:
github:
owner: my-org-or-user
repo: my-repo
pullRequestId: 1234
tokenRef:
secretName: git-credentials
key: github-token
comment:
source:
configMap:
name: my-configmap
key: my-key
comment.source.textTemplate
Uses a TextTemplate as source for the comment’s content. Example:
apiVersion: templates.kluctl.io/v1alpha1
kind: TextTemplate
metadata:
name: my-texttemplate
namespace: default
spec:
inputs:
... # See TextTemplate documentation for details.
template: |
This can by **any** form of [Markdown](https://en.wikipedia.org/wiki/Markdown) supported by Github.
---
apiVersion: templates.kluctl.io/v1alpha1
kind: GithubComment
metadata:
name: comment-gh
namespace: default
spec:
github:
owner: my-org-or-user
repo: my-repo
pullRequestId: 1234
tokenRef:
secretName: git-credentials
key: github-token
comment:
source:
textTemplate:
name: my-texttemplate
7.2.1.4 - GitlabComment
The GitlabComment API allows to post a comment to a Gitlab Merge Request.
Example
apiVersion: v1
kind: ConfigMap
metadata:
name: my-configmap
namespace: default
data:
my-key: |
This can by **any** form of [Markdown](https://en.wikipedia.org/wiki/Markdown) supported by Gitlab.
---
apiVersion: templates.kluctl.io/v1alpha1
kind: GitlabComment
metadata:
name: comment-gl
namespace: default
spec:
gitlab:
project: my-group/my-repo
mergeRequestId: 1234
tokenRef:
secretName: git-credentials
key: gitlab-token
comment:
source:
configMap:
name: my-configmap
key: my-key
The above example will post a comment to the specified pull request. The comment’s content is loaded from the ConfigMap
my-configmap. Other sources are also supported, see the source field documentation for details.
The comment will be updated whenever the underlying comment source changes.
Spec fields
suspend
If set to true, reconciliation of this comment is suspended.
gitlab
Specifies which Gitlab project and merge request to post the comment to.
gitlab.project
Specifies the user or organisation name where the repository is localed.
gitlab.repo
Specifies the repository name to query PRs for.
gitlab.tokenRef
In case of private repositories, this field can be used to specify a secret that contains a Gitlab API token.
github.pullRequestId
Specifies the ID of the pull request.
comment
Same as in GithubComment
7.2.1.5 - ListGithubPullRequests
The ListGithubPullRequests API allows to query the GitHub API for a list of pull requests (PRs). These PRs
can be filtered when needed. The resulting list of PRs is written into the status of the
ListGithubPullRequests object.
The resulting PRs list inside the status can for example be used in ObjectTemplate to create objects based on
pull requests.
Example
apiVersion: templates.kluctl.io/v1alpha1
kind: ListGithubPullRequests
metadata:
name: list-gh-prs
namespace: default
spec:
interval: 1m
owner: podtato-head
repo: podtato-head
state: open
base: main
head: podtato-head:.*
tokenRef:
secretName: git-credentials
key: github-token
The above example will regularly (1m interval) query the GitHub API for PRs inside the podtato-head repository. It will filter for open PRs and for PRs against the main branch.
Spec fields
interval
Specifies the interval in which to query the GitHub API. Defaults to 5m.
owner
Specifies the user or organisation name where the repository is localed.
repo
Specifies the repository name to query PRs for.
tokenRef
In case of private repositories, this field can be used to specify a secret that contains a GitHub API token.
head
Specifies the head to filter PRs for. The format must be user:ref-name / organization:ref-name. The head
field can also contain regular expressions.
base
Specifies the base branch to filter PRs for. The base field can also contain regular expressions.
labels
Specifies a list of labels to filter PRs for.
state
Specifies the PR state to filter for. Can either be open, closed or all. Default to all.
limit
Limits the number of results to accept. This is a safeguard for repositories with hundreds/thousands of PRs. It defaults to 100.
Resulting status
The query result is written into the status.pullRequests field of the ListGithubPullRequests object. Each entry
represents a reduced version of the GitHub Pulls API
results. The result is reduced in verbosity to avoid overloading the Kubernetes apiserver. Reduction means that all
fields containing user, repo, orga and label fields are reduced to id, name, login, owner and
full_name.
Please note that the resulting PR objects do not follow the typical camel case notion found in CRDs, as these represent a copy of GitHub API objects.
Example:
apiVersion: templates.kluctl.io/v1alpha1
kind: ListGithubPullRequests
metadata:
name: list-gh-prs
namespace: default
spec:
...
status:
conditions:
- lastTransitionTime: "2022-11-07T14:55:36Z"
message: Success
observedGeneration: 3
reason: Success
status: "True"
type: Ready
pullRequests:
- base:
label: podtato-head:main
ref: main
repo:
full_name: podtato-head/podtato-head
name: podtato-head
sha: de7e66af16d41b0ef83de9a0b3be6f5cf0caf942
body: "..."
created_at: "2022-02-02T23:06:28Z"
head:
label: vivek:issue-79_implement_ms_ketch
ref: issue-79_implement_ms_ketch
repo:
full_name: vivek/podtato-head
name: podtato-head
sha: 6379b4c8f413dae70daa03a5a13de4267486fd59
number: 151
state: open
title: '...'
updated_at: "2022-02-04T03:53:03Z"
7.2.1.6 - TextTemplate
GithubComment
The TextTemplate API allows to define text templates that are rendered into the status of the TextTemplate.
The result can for example be used in GitlabComment/GithubComment.
Example
For the below example to work, you will also have to deploy the RBAC resources documented in ObjectTemplate.
apiVersion: v1
kind: ConfigMap
metadata:
name: my-configmap
namespace: default
data:
mykey: input-value
---
apiVersion: templates.kluctl.io/v1alpha1
kind: TextTemplate
metadata:
name: example
namespace: default
spec:
serviceAccountName: example-template-service-account
inputs:
- name: input1
object:
ref:
apiVersion: v1
kind: ConfigMap
name: my-configmap
template: |
This template text can use variables from the inputs defined above, for example this: {{ inputs.input1.data.mykey }}.
The above example will render the given template text and write it into the result of the object:
apiVersion: templates.kluctl.io/v1alpha1
kind: TextTemplate
...
status:
conditions:
- lastTransitionTime: "2023-01-16T11:24:15Z"
message: Success
observedGeneration: 2
reason: Success
status: "True"
type: Ready
result: 'This template text can use variables from the inputs defined above, for example this: input-value.'
Spec fields
suspend
If set to true, reconciliation of this TextTemplate is suspended.
serviceAccountName
The service account to use while retrieving template inputs. See the ObjectTemplate documentation for details.
inputs
List of template inputs which are then available while rendering the text template. At the moment, only Kubernetes objects are supported as inputs, but other types of inputs might be supported in the future.
Example:
apiVersion: templates.kluctl.io/v1alpha1
kind: TextTemplate
metadata:
name: example
namespace: default
spec:
serviceAccountName: example-template-service-account
inputs:
- name: input1
object:
ref:
apiVersion: v1
kind: ConfigMap
name: my-configmap
namespace: default
jsonPath: data
template: |
This template text can use variables from the inputs defined above, for example this: {{ inputs.input1.mykey }}.
inputs.name
Specifies the name of the input, which is then used to refer to the input inside the text template.
inputs.object
Specifies the object to load as input. The specified service account must have proper permissions to access this object.
template
Specifies the raw template text to be rendered in the reconciliation loop. While rendering, each input is available
via the global inputs variable and the specified name of the input, e.g. `{{ inputs.my_input.sub_field }}.
See templating for more details on the templating engine.
templateRef
Specifies another object to load the template text from. Currently only ConfigMaps are supported.
templateRef.configMap:
Specifies a ConfigMap to load the template from.
Example:
apiVersion: v1
kind: ConfigMap
metadata:
name: my-configmap
namespace: default
data:
mykey: input-value
---
apiVersion: v1
kind: ConfigMap
metadata:
name: my-template
namespace: default
data:
template: |
This template text can use variables from the inputs defined above, for example this: {{ inputs.input1.data.mykey }}.
---
apiVersion: templates.kluctl.io/v1alpha1
kind: TextTemplate
metadata:
name: example
namespace: default
spec:
serviceAccountName: example-template-service-account
inputs:
- name: input1
object:
ref:
apiVersion: v1
kind: ConfigMap
name: my-configmap
templateRef:
configMap:
name: my-template
key: template
Resulting status
The resulting rendered template is written into the status and can then be used by other objects, e.g. GitlabComment/GithubComment.
Example:
...
status:
conditions:
- lastTransitionTime: "2023-01-16T11:24:15Z"
message: Success
observedGeneration: 3
reason: Success
status: "True"
type: Ready
result: 'This template text can use variables from the inputs defined above,
for example this: input-value.'
7.2.1.7 - ListGitlabMergeRequests
The ListGitlabMergeRequests API allows to query the Gitlab API for a list of merge requests (MRs). These MRs
can be filtered when needed. The resulting list of MRs is written into the status of the
ListGitlabMergeRequests object.
The resulting MRs list inside the status can for example be used in ObjectTemplate to create objects based on
pull requests.
Example
apiVersion: templates.kluctl.io/v1alpha1
kind: ListGitlabMergeRequests
metadata:
name: list-gl-mrs
namespace: default
spec:
interval: 1m
project: my-group/my-repo
state: opened
targetBranch: main
sourceBranch: prefix-.*
tokenRef:
secretName: git-credentials
key: gitlab-token
The above example will regularly (1m interval) query the Gitlab API for MRs inside the my-group/my-repo
project. It will filter for open MRs and for MRs against the main branch.
Spec fields
interval
Specifies the interval in which to query the GitHub API. Defaults to 5m.
project
Specifies the Gitlab project to query MRs for. Must be in the format group/project, where group can also contain
subgroups (e.g. group1/group2/project).
tokenRef
In case of private repositories, this field can be used to specify a secret that contains a Gitlab API token.
targetBranch
Specifies the target branch to filter MRs for. The targetBranch field can also contain regular expressions.
sourceBranch
Specifies the source branch to filter MRs for. The sourceBranch field can also contain regular expressions.
labels
Specifies a list of labels to filter MRs for.
state
Specifies the PR state to filter for. Can either be opened, closed, locked, merged or all. Default to all.
limit
Limits the number of results to accept. This is a safeguard for repositories with hundreds/thousands of MRs. It defaults to 100.
Resulting status
The query result is written into the status.mergeRequests field of the ListGitlabMergeRequests object. The list is
identical to what is documented in the Gitlab Merge requests API.
Please note that the resulting PR objects do not follow the typical camel case notion found in CRDs, as these represent a copy of Gitlab API objects.
Example:
apiVersion: templates.kluctl.io/v1alpha1
kind: ListGitlabMergeRequests
metadata:
name: list-gl-mrs
namespace: default
spec:
...
status:
conditions:
- lastTransitionTime: "2022-11-07T14:55:36Z"
message: Success
observedGeneration: 3
reason: Success
status: "True"
type: Ready
mergeRequests:
- id: 1
iid: 1
project_id: 3
title: test1
description: fixed login page css paddings
state: merged
merged_by:
id: 87854
name: Douwe Maan
username: DouweM
state: active
avatar_url: 'https://gitlab.example.com/uploads/-/system/user/avatar/87854/avatar.png'
web_url: 'https://gitlab.com/DouweM'
merge_user:
id: 87854
name: Douwe Maan
username: DouweM
state: active
avatar_url: 'https://gitlab.example.com/uploads/-/system/user/avatar/87854/avatar.png'
web_url: 'https://gitlab.com/DouweM'
merged_at: '2018-09-07T11:16:17.520Z'
closed_by: null
closed_at: null
created_at: '2017-04-29T08:46:00Z'
updated_at: '2017-04-29T08:46:00Z'
target_branch: master
source_branch: test1
upvotes: 0
downvotes: 0
author:
id: 1
name: Administrator
username: admin
state: active
avatar_url: null
web_url: 'https://gitlab.example.com/admin'
assignee:
id: 1
name: Administrator
username: admin
state: active
avatar_url: null
web_url: 'https://gitlab.example.com/admin'
assignees:
- name: Miss Monserrate Beier
username: axel.block
id: 12
state: active
avatar_url: >-
http://www.gravatar.com/avatar/46f6f7dc858ada7be1853f7fb96e81da?s=80&d=identicon
web_url: 'https://gitlab.example.com/axel.block'
reviewers:
- id: 2
name: Sam Bauch
username: kenyatta_oconnell
state: active
avatar_url: >-
https://www.gravatar.com/avatar/956c92487c6f6f7616b536927e22c9a0?s=80&d=identicon
web_url: 'http://gitlab.example.com//kenyatta_oconnell'
source_project_id: 2
target_project_id: 3
labels:
- Community contribution
- Manage
draft: false
work_in_progress: false
milestone:
id: 5
iid: 1
project_id: 3
title: v2.0
description: Assumenda aut placeat expedita exercitationem labore sunt enim earum.
state: closed
created_at: '2015-02-02T19:49:26.013Z'
updated_at: '2015-02-02T19:49:26.013Z'
due_date: '2018-09-22'
start_date: '2018-08-08'
web_url: 'https://gitlab.example.com/my-group/my-project/milestones/1'
merge_when_pipeline_succeeds: true
merge_status: can_be_merged
detailed_merge_status: not_open
sha: '8888888888888888888888888888888888888888'
merge_commit_sha: null
squash_commit_sha: null
user_notes_count: 1
discussion_locked: null
should_remove_source_branch: true
force_remove_source_branch: false
allow_collaboration: false
allow_maintainer_to_push: false
web_url: 'http://gitlab.example.com/my-group/my-project/merge_requests/1'
references:
short: '!1'
relative: my-group/my-project!1
full: my-group/my-project!1
time_stats:
time_estimate: 0
total_time_spent: 0
human_time_estimate: null
human_total_time_spent: null
squash: false
task_completion_status:
count: 0
completed_count: 0
7.3 - Security
The Template Controller is a powerful controller that is able to create/apply arbitrary objects from templates and an input matrix. This has some security implications as it requires you to make sure that you don’t open potential security vulnerabilities inside your cluster.
This means, you must make sure that your ObjectTemplate objects are either not dependent on external inputs (which
might contain malicious input) or tha the used service account
is restricted enough to not allow malicious modifications to the cluster.
cluster-admin role
Especially watch out when using the cluster-admin (or comparable) role. It can easily lead to privilege escalation if templates and inputs are too dynamic.
7.4 - Templating
The Template Controller reuses the Jinja2 templating engine of Kluctl.
Documentation is available here.
Predefined variables
You can use multiple predefined variables in your templates. These are:
objectTemplate
Available in templates inside ObjectTemplate and represents the whole
ObjectTemplate that was on your target BEFORE the reconciliation started.
textTemplate
Available in templates inside TextTemplate and represents the whole
TextTemplate that was on your target BEFORE the reconciliation started.
7.5 - Use Case: Dynamic environments for Pull Requests
This use case was the initial and first use case why the Template Controller was created. You can use ListGithubPullRequests
to query the GitHub API for a list of pull requests on a GitHub Repo and then use the result inside a ObjectTemplate
to generate GitOps environments for new pull requests.
Flux
This example will create templated Kustomization objects. The means, that you should first install Flux on your cluster. The dev install variant should be sufficient.
podtato-head as example
This example uses the podtato-head demo project to demonstrate the
Template Controller. You must fork the repository and replace all occurrences of podtato-head as owner with your
own username. It is not recommended to blindly use the public repository as you this will lead to unverified and
potentially dangerous environments being deployed into your cluster!
GitHub credentials
In case you want to listen for PRs from a private repository (e.g. because you’ve forked podtato-head), you’ll need to store a GitHub personal access token inside a Kubernetes Secret.
apiVersion: v1
kind: Secret
metadata:
name: git-credentials
namespace: default
stringData:
github-token: "<your-github-token>"
WARNING: Of course, in a real setup you would NOT store the plain token inside a manifest, but instead use Sealed Secrets or SOPS.
A dedicated ServiceAccount
The Template Controller uses service accounts to query matrix inputs and apply rendered objects. These service accounts
determine what the template can access and what not. In this example, we’ll create a service account with the
cluster-admin role, which you should NOT do in production. Instead, define your own Role or ClusterRole and
attach it to the service account. This role should have read/write access to all objects references in the matrix and
the rendered objects.
apiVersion: v1
kind: ServiceAccount
metadata:
name: podtato-head-envs-objecttemplate
namespace: default
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: podtato-head-envs-objecttemplate
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
# WARNING, this is only for demo purposes. You should use a more restricted role for the ObjectTemplate
name: cluster-admin
subjects:
- kind: ServiceAccount
name: podtato-head-envs-objecttemplate
namespace: default
The above serviceAccount is then later referenced inside the ObjectTemplate object.
Listing GitHub pull requests
Listing pull requests from a GitHub repository can be done through the
ListGithubPullRequests CRD. It specifies the GitHub repository to use and
some filter options.
apiVersion: templates.kluctl.io/v1alpha1
kind: ListGithubPullRequests
metadata:
name: list-gh-prs
namespace: default
spec:
interval: 1m
# Replace the owner with your username in case you forked podtato-head
owner: podtato-head
repo: podtato-head
# Ignore closed PRs
state: open
# Only PR's that go against the main branch
base: main
# Replace `podtato-head` with your username. This will only allows heads from your own fork!
# Otherwise, you risk deploying unsafe environments into your cluster!
head: podtato-head:.*
tokenRef:
secretName: git-credentials
key: github-token
After applying this resource, the Template Controller will start to query the GitHub API for matching pull requests and
then store the results inside the status of the ListGithubPullRequests CR. Example:
apiVersion: templates.kluctl.io/v1alpha1
kind: ListGithubPullRequests
metadata:
name: list-gh-prs
namespace: default
spec:
...
status:
conditions:
- lastTransitionTime: "2022-11-07T14:55:36Z"
message: Success
observedGeneration: 3
reason: Success
status: "True"
type: Ready
# The pullRequests list contains much more detailed info, but to keep it short I've reduced verbosity here
pullRequests:
- base:
label: podtato-head:main
ref: main
repo:
full_name: podtato-head/podtato-head
name: podtato-head
sha: de7e66af16d41b0ef83de9a0b3be6f5cf0caf942
body: "..."
created_at: "2022-02-02T23:06:28Z"
head:
label: vivek:issue-79_implement_ms_ketch
ref: issue-79_implement_ms_ketch
repo:
full_name: vivek/podtato-head
name: podtato-head
sha: 6379b4c8f413dae70daa03a5a13de4267486fd59
number: 151
state: open
title: '...'
updated_at: "2022-02-04T03:53:03Z"
The ObjectTemplate
The pullRequests field from the above status can then be used as an input into the an
ObjectTemplate.
apiVersion: templates.kluctl.io/v1alpha1
kind: ObjectTemplate
metadata:
name: pr-envs
namespace: default
spec:
serviceAccountName: podtato-head-envs-objecttemplate
# This causes removal of templated objects in case they disappear from the rendered list of objects
prune: true
matrix:
- name: pr
object:
ref:
apiVersion: templates.kluctl.io/v1alpha1
kind: ListGithubPullRequests
name: list-gh-prs
jsonPath: status.pullRequests
expandLists: true
templates:
- object:
apiVersion: v1
kind: Namespace
metadata:
# Give each one its own namespace
name: "podtato-head-{{ matrix.pr.head.label | slugify }}"
- object:
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: GitRepository
metadata:
# The pullRequests status field from the ListGithubPullRequests is a reduced form of the REST API result
# of https://docs.github.com/en/rest/pulls/pulls#list-pull-requests, meaning that fields like `head` and `base`
# are also available.
name: "podtato-head-{{ matrix.pr.head.label | slugify }}"
namespace: default
spec:
interval: 5m
url: "https://github.com/{{ matrix.pr.head.repo.full_name }}.git"
ref:
branch: "{{ matrix.pr.head.ref }}"
- object:
apiVersion: kustomize.toolkit.fluxcd.io/v1beta2
kind: Kustomization
metadata:
name: "podtato-head-env-{{ matrix.pr.head.label | slugify }}"
namespace: default
spec:
interval: 10m
targetNamespace: "podtato-head-{{ matrix.pr.head.label | slugify }}"
sourceRef:
kind: GitRepository
# refers to the same GitRepository created above
name: "podtato-head-{{ matrix.pr.head.label | slugify }}"
path: "./delivery/kustomize/base"
prune: true
The above ObjectTemplate will create 3 objects per pull request:
- A namespace with the name
podtato-head-{{ matrix.pr.head.label | slugify }}. Please note the use of Jinja2 templating. Details about what can be done can be found in theObjectTemplatedocumentation. - A Flux GitRepository that points to repository and branch of the current pull request.
- A Flux Kustomization that is deployed into the above namespace.
7.6 - Use Case: Transformation of Secrets/Objects
There are cases where an object can not be created before another object is created by some other component inside the cluster, meaning that you have no control over the input object.
A simple example is the Zalando Postgres Operator, which allows you to create a Postgres database with a Custom Resource. Inside the CR, you can define databases and users to be auto-created. When the operator creates these databases and users, it also auto-creates Kubernetes secrets with the credentials allowing you to access the databases.
These secrets can however not be used directly when connecting to the databases, as you’d usually have to build some connection urls (e.g. JDBC urls). Usually, one would create some kind of init script or something like that to build this url and then pass it to the application that wants to use it.
The Template Controller allows an alternative solution.
Using ObjectTemplate to transform secrets
Let’s assume you have a sample Postgres database deployed via the Zalando Postgres Operator. The operator has also created the following secret:
apiVersion: v1
kind: Secret
type: Opaque
metadata:
name: foo-user.acid-minimal-cluster.credentials.postgresql.acid.zalan.do
namespace: default
data:
password: aHNiSVF6MFJJa0hTd2ZxS1NiTG5YV3dUQUVqcUtTNFpvU2dyOXp4b3pzMmJvTE02WWl0eTE0YjJTZlNFTHExdw==
username: Zm9vX3VzZXI=
Based on that secret, you’d like to create a new secret with the JDBC url generated.
RBAC
The ObjectTemplate requires a service account with proper access rights for the involved secrets:
apiVersion: v1
kind: ServiceAccount
metadata:
name: postgres-secret-transformer
namespace: default
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: postgres-secret-transformer
namespace: default
rules:
- apiGroups: [""]
resources: ["secrets"]
# give the ObjectTemplate access to the two involved secrets
resourceNames: ["zalando.acid-minimal-cluster.credentials.postgresql.acid.zalan.do", "transformed-postgres-secret"]
verbs: ["*"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: postgres-secret-transformer
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: postgres-secret-transformer
subjects:
- kind: ServiceAccount
name: postgres-secret-transformer
namespace: default
ObjectTemplate
Use the following ObjectTemplate to perform the transformation:
apiVersion: templates.kluctl.io/v1alpha1
kind: ObjectTemplate
metadata:
name: postgres-secret-transformer
namespace: default
spec:
serviceAccountName: postgres-secret-transformer
prune: true
matrix:
- name: secret
object:
ref:
apiVersion: v1
kind: Secret
name: zalando.acid-minimal-cluster.credentials.postgresql.acid.zalan.do
templates:
- object:
apiVersion: v1
kind: Secret
metadata:
name: "transformed-postgres-secret"
stringData:
jdbc_url: "jdbc:postgresql://acid-minimal-cluster/zalando?user={{ matrix.secret.data.username | b64decode }}&password={{ matrix.secret.data.password | b64decode }}"
# sometimes the key names inside a secret are not what another component requires, so we can simply use different names if we want
username_with_different_key: "{{ matrix.secret.data.username | b64decode }}"
password_with_different_key: "{{ matrix.secret.data.password | b64decode }}"
This will lead to the following transformed-postgres-secret
apiVersion: v1
kind: Secret
metadata:
name: transformed-postgres-secret
namespace: default
type: Opaque
data:
jdbc_url: amRiYzpwb3N0Z3Jlc3FsOi8vaG9zdC9kYXRhYmFzZT91c2VyPWZvb191c2VyJnBhc3N3b3JkPWJVUU52Zkd4amduQUdiaEhOWkZkamtwZFFYbnk1aDdXNGlFU1YyWUxVNnVrRHdXWjBPMjdRb0NBdUJTTnF3TVk=
password_with_different_key: YlVRTnZmR3hqZ25BR2JoSE5aRmRqa3BkUVhueTVoN1c0aUVTVjJZTFU2dWtEd1daME8yN1FvQ0F1QlNOcXdNWQ==
username_with_different_key: Zm9vX3VzZXI=
Base64 decoding the secret data will show:
jdbc_url: jdbc:postgresql://host/database?user=foo_user&password=bUQNvfGxjgnAGbhHNZFdjkpdQXny5h7W4iESV2YLU6ukDwWZ0O27QoCAuBSNqwMY │
password_with_different_key: bUQNvfGxjgnAGbhHNZFdjkpdQXny5h7W4iESV2YLU6ukDwWZ0O27QoCAuBSNqwMY │
username_with_different_key: foo_user
7.7 - Template Controller API reference
Packages:
templates.kluctl.io/v1alpha1
Package v1alpha1 contains API Schema definitions for the templates.kluctl.io v1alpha1 API group.
Resource Types:AppliedResourceInfo
(Appears on: ObjectTemplateStatus)
| Field | Description |
|---|---|
refObjectRef | |
successbool | |
errorstring | (Optional) |
CommentSourceSpec
(Appears on: CommentSpec)
| Field | Description |
|---|---|
textstring | (Optional) Text specifies a raw text comment. |
configMapConfigMapRef | (Optional) ConfigMap specifies a ConfigMap and a key to load the source content from |
textTemplateLocalObjectReference | (Optional) TextTemplate specifies a TextTemplate to load the source content from |
CommentSpec
(Appears on: GithubCommentSpec, GitlabCommentSpec)
| Field | Description |
|---|---|
idstring | (Optional) Id specifies the identifier to be used by the controller when it needs to find the actual comment when it does not know the internal id. This Id is written into the comment inside a comment, so that a simple text search can reveal the comment |
sourceCommentSourceSpec | Source specifies the source content for the comment. Different source types are supported: Text, ConfigMap and TextTemplate |
ConfigMapRef
(Appears on: CommentSourceSpec)
| Field | Description |
|---|---|
namestring | |
keystring |
GitFile
(Appears on: GitProjectorSpec)
| Field | Description |
|---|---|
globstring | Glob specifies a glob to use for filename matching. |
parseYamlbool | (Optional) ParseYaml enables YAML parsing of matching files. The result is then available as |
GitProjector
GitProjector is the Schema for the gitprojectors API
| Field | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta | Refer to the Kubernetes API documentation for the fields of the
metadata field. | ||||||||||||
specGitProjectorSpec |
| ||||||||||||
statusGitProjectorStatus |
GitProjectorResult
(Appears on: GitProjectorStatus)
| Field | Description |
|---|---|
refGitRef | |
files[]GitProjectorResultFile |
GitProjectorResultFile
(Appears on: GitProjectorResult)
| Field | Description |
|---|---|
pathstring | |
rawstring | (Optional) |
parsed[]*k8s.io/apimachinery/pkg/runtime.RawExtension | (Optional) |
GitProjectorSpec
(Appears on: GitProjector)
GitProjectorSpec defines the desired state of GitProjector
| Field | Description |
|---|---|
intervalKubernetes meta/v1.Duration | (Optional) Interval is the interval at which to scan the Git repository Defaults to 5m. |
suspendbool | (Optional) Suspend can be used to suspend the reconciliation of this object |
urlstring | URL specifies the Git url to scan and project |
refGitRef | (Optional) Reference specifies the Git branch, tag or commit to scan. Branches and tags can contain regular expressions |
files[]GitFile | (Optional) Files specifies the list of files to include in the projection |
secretRefLocalObjectReference | (Optional) SecretRefs specifies a Secret use for Git authentication. The contents of the secret must conform to: https://kluctl.io/docs/flux/spec/v1alpha1/kluctldeployment/#git-authentication |
GitProjectorStatus
(Appears on: GitProjector)
GitProjectorStatus defines the observed state of GitProjector
| Field | Description |
|---|---|
conditions[]Kubernetes meta/v1.Condition | (Optional) |
allRefsHashstring | (Optional) |
result[]GitProjectorResult | (Optional) |
GitRef
(Appears on: GitProjectorResult, GitProjectorSpec)
| Field | Description |
|---|---|
branchstring | (Optional) Branch to filter for. Can also be a regex. |
tagstring | (Optional) Tag to filter for. Can also be a regex. |
commitstring | (Optional) Commit SHA to check out, takes precedence over all reference fields. |
GithubComment
GithubComment is the Schema for the githubcomments API
| Field | Description | ||||||
|---|---|---|---|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta | Refer to the Kubernetes API documentation for the fields of the
metadata field. | ||||||
specGithubCommentSpec |
| ||||||
statusGithubCommentStatus |
GithubCommentSpec
(Appears on: GithubComment)
GithubCommentSpec defines the desired state of GithubComment
| Field | Description |
|---|---|
githubGithubPullRequestRef | |
commentCommentSpec | |
suspendbool | (Optional) Suspend can be used to suspend the reconciliation of this object |
GithubCommentStatus
(Appears on: GithubComment)
GithubCommentStatus defines the observed state of GithubComment
| Field | Description |
|---|---|
conditions[]Kubernetes meta/v1.Condition | (Optional) |
commentIdstring | (Optional) |
lastPostedBodyHashstring | (Optional) |
GithubProject
(Appears on: GithubPullRequestRef, ListGithubPullRequestsSpec)
| Field | Description |
|---|---|
ownerstring | Owner specifies the GitHub user or organisation that owns the repository |
repostring | Repo specifies the repository name. |
tokenRefSecretRef | (Optional) TokenRef specifies a secret and key to load the GitHub API token from |
GithubPullRequestRef
(Appears on: GithubCommentSpec)
| Field | Description |
|---|---|
GithubProjectGithubProject | (Members of |
pullRequestIdk8s.io/apimachinery/pkg/util/intstr.IntOrString | PullRequestId specifies the pull request ID. |
GitlabComment
GitlabComment is the Schema for the gitlabcomments API
| Field | Description | ||||||
|---|---|---|---|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta | Refer to the Kubernetes API documentation for the fields of the
metadata field. | ||||||
specGitlabCommentSpec |
| ||||||
statusGitlabCommentStatus |
GitlabCommentSpec
(Appears on: GitlabComment)
GitlabCommentSpec defines the desired state of GitlabComment
| Field | Description |
|---|---|
gitlabGitlabMergeRequestRef | |
commentCommentSpec | |
suspendbool | (Optional) Suspend can be used to suspend the reconciliation of this object |
GitlabCommentStatus
(Appears on: GitlabComment)
GitlabCommentStatus defines the observed state of GitlabComment
| Field | Description |
|---|---|
conditions[]Kubernetes meta/v1.Condition | (Optional) |
noteIdstring | (Optional) |
lastPostedBodyHashstring | (Optional) |
GitlabMergeRequestRef
(Appears on: GitlabCommentSpec)
| Field | Description |
|---|---|
GitlabProjectGitlabProject | (Members of |
mergeRequestIdk8s.io/apimachinery/pkg/util/intstr.IntOrString | MergeRequestId specifies the Gitlab merge request internal ID |
GitlabProject
(Appears on: GitlabMergeRequestRef, ListGitlabMergeRequestsSpec)
| Field | Description |
|---|---|
projectk8s.io/apimachinery/pkg/util/intstr.IntOrString | Project specifies the Gitlab group and project (separated by slash) to use, or the numeric project id |
apistring | (Optional) API specifies the GitLab API URL to talk to. If blank, uses https://gitlab.com/. |
tokenRefSecretRef | (Optional) TokenRef specifies a secret and key to load the Gitlab API token from |
ListGithubPullRequests
ListGithubPullRequests is the Schema for the listgithubpullrequests API
| Field | Description | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta | Refer to the Kubernetes API documentation for the fields of the
metadata field. | ||||||||||||||
specListGithubPullRequestsSpec |
| ||||||||||||||
statusListGithubPullRequestsStatus |
ListGithubPullRequestsSpec
(Appears on: ListGithubPullRequests)
ListGithubPullRequestsSpec defines the desired state of ListGithubPullRequests
| Field | Description |
|---|---|
intervalKubernetes meta/v1.Duration | (Optional) Interval is the interval at which to query the Gitlab API. Defaults to 5m. |
GithubProjectGithubProject | (Members of |
headstring | (Optional) Head specifies the head to filter for |
basestring | (Optional) Base specifies the base to filter for |
labels[]string | (Optional) Labels is used to filter the PRs that you want to target |
statestring | (Optional) State is an additional PR filter to get only those with a certain state. Default: “all” |
limitint | Limit limits the maximum number of pull requests to fetch. Defaults to 100 |
ListGithubPullRequestsStatus
(Appears on: ListGithubPullRequests)
ListGithubPullRequestsStatus defines the observed state of ListGithubPullRequests
| Field | Description |
|---|---|
conditions[]Kubernetes meta/v1.Condition | (Optional) |
pullRequests[]k8s.io/apimachinery/pkg/runtime.RawExtension | (Optional) |
ListGitlabMergeRequests
ListGitlabMergeRequests is the Schema for the listgitlabmergerequests API
| Field | Description | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta | Refer to the Kubernetes API documentation for the fields of the
metadata field. | ||||||||||||||
specListGitlabMergeRequestsSpec |
| ||||||||||||||
statusListGitlabMergeRequestsStatus |
ListGitlabMergeRequestsSpec
(Appears on: ListGitlabMergeRequests)
ListGitlabMergeRequestsSpec defines the desired state of ListGitlabMergeRequests
| Field | Description |
|---|---|
intervalKubernetes meta/v1.Duration | (Optional) Interval is the interval at which to query the Gitlab API. Defaults to 5m. |
GitlabProjectGitlabProject | (Members of |
targetBranchstring | (Optional) TargetBranch specifies the target branch to filter for |
sourceBranchstring | (Optional) |
labels[]string | (Optional) Labels is used to filter the MRs that you want to target |
statestring | (Optional) State is an additional MRs filter to get only those with a certain state. Default: “all” |
limitint | Limit limits the maximum number of merge requests to fetch. Defaults to 100 |
ListGitlabMergeRequestsStatus
(Appears on: ListGitlabMergeRequests)
ListGitlabMergeRequestsStatus defines the observed state of ListGitlabMergeRequests
| Field | Description |
|---|---|
conditions[]Kubernetes meta/v1.Condition | (Optional) |
mergeRequests[]k8s.io/apimachinery/pkg/runtime.RawExtension | (Optional) |
LocalObjectReference
(Appears on: CommentSourceSpec, GitProjectorSpec)
| Field | Description |
|---|---|
namestring | Name of the referent. |
MatrixEntry
(Appears on: ObjectTemplateSpec)
| Field | Description |
|---|---|
namestring | Name specifies the name this matrix input is available while rendering templates |
objectMatrixEntryObject | (Optional) Object specifies an object to load and make available while rendering templates. The object can be accessed through the name specified above. The service account used by the ObjectTemplate must have proper permissions to get this object |
list[]k8s.io/apimachinery/pkg/runtime.RawExtension | (Optional) List specifies a list of plain YAML values which are made available while rendering templates. The list can be accessed through the name specified above |
MatrixEntryObject
(Appears on: MatrixEntry)
| Field | Description |
|---|---|
refObjectRef | Ref specifies the apiVersion, kind, namespace and name of the object to load. The service account used by the ObjectTemplate must have proper permissions to get this object |
jsonPathstring | (Optional) JsonPath optionally specifies a sub-field to load. When specified, the sub-field (and not the whole object) is made available while rendering templates |
expandListsbool | (Optional) ExpandLists enables optional expanding of list. Expanding means, that each list entry is interpreted as
individual matrix input instead of interpreting the whole list as one matrix input. This feature is only useful
when used in combination with |
ObjectRef
(Appears on: AppliedResourceInfo, MatrixEntryObject, TextTemplateInputObject)
| Field | Description |
|---|---|
apiVersionstring | |
kindstring | |
namespacestring | (Optional) |
namestring |
ObjectTemplate
ObjectTemplate is the Schema for the objecttemplates API
| Field | Description | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta | Refer to the Kubernetes API documentation for the fields of the
metadata field. | ||||||||||||
specObjectTemplateSpec |
| ||||||||||||
statusObjectTemplateStatus |
ObjectTemplateSpec
(Appears on: ObjectTemplate)
ObjectTemplateSpec defines the desired state of ObjectTemplate
| Field | Description |
|---|---|
intervalKubernetes meta/v1.Duration | |
suspendbool | (Optional) Suspend can be used to suspend the reconciliation of this object |
serviceAccountNamestring | (Optional) ServiceAccountName specifies the name of the Kubernetes service account to impersonate when reconciling this ObjectTemplate. If omitted, the “default” service account is used |
prunebool | (Optional) Prune enables pruning of previously created objects when these disappear from the list of rendered objects |
matrix[]MatrixEntry | Matrix specifies the input matrix |
templates[]Template | Templates specifies a list of templates to render and deploy |
ObjectTemplateStatus
(Appears on: ObjectTemplate)
ObjectTemplateStatus defines the observed state of ObjectTemplate
| Field | Description |
|---|---|
conditions[]Kubernetes meta/v1.Condition | (Optional) |
appliedResources[]AppliedResourceInfo | (Optional) |
SecretRef
(Appears on: GithubProject, GitlabProject)
Utility struct for a reference to a secret key.
| Field | Description |
|---|---|
secretNamestring | |
keystring |
Template
(Appears on: ObjectTemplateSpec)
| Field | Description |
|---|---|
objectKubernetes meta/v1/unstructured.Unstructured | (Optional) Object specifies a structured object in YAML form. Each field value is rendered independently. |
rawstring | (Optional) Raw specifies a raw string to be interpreted/parsed as YAML. The whole string is rendered in one go, allowing to use advanced Jinja2 control structures. Raw object might also be required when a templated value must not be interpreted as a string (which would be done in Object). |
TemplateRef
(Appears on: TextTemplateSpec)
| Field | Description |
|---|---|
configMapTemplateRefConfigMap | (Optional) |
TemplateRefConfigMap
(Appears on: TemplateRef)
| Field | Description |
|---|---|
namestring | |
namespacestring | (Optional) |
keystring |
TextTemplate
TextTemplate is the Schema for the texttemplates API
| Field | Description | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
metadataKubernetes meta/v1.ObjectMeta | Refer to the Kubernetes API documentation for the fields of the
metadata field. | ||||||||||
specTextTemplateSpec |
| ||||||||||
statusTextTemplateStatus |
TextTemplateInput
(Appears on: TextTemplateSpec)
| Field | Description |
|---|---|
namestring | |
objectTextTemplateInputObject | (Optional) |
TextTemplateInputObject
(Appears on: TextTemplateInput)
| Field | Description |
|---|---|
refObjectRef | |
jsonPathstring | (Optional) |
TextTemplateSpec
(Appears on: TextTemplate)
TextTemplateSpec defines the desired state of TextTemplate
| Field | Description |
|---|---|
suspendbool | (Optional) Suspend can be used to suspend the reconciliation of this object. |
serviceAccountNamestring | (Optional) ServiceAccountName specifies the name of the Kubernetes service account to impersonate when reconciling this TextTemplate. If omitted, the “default” service account is used |
inputs[]TextTemplateInput | (Optional) |
templatestring | (Optional) |
templateRefTemplateRef | (Optional) |
TextTemplateStatus
(Appears on: TextTemplate)
TextTemplateStatus defines the observed state of TextTemplate
| Field | Description |
|---|---|
conditions[]Kubernetes meta/v1.Condition | (Optional) |
resultstring | (Optional) |
This page was automatically generated with gen-crd-api-reference-docs